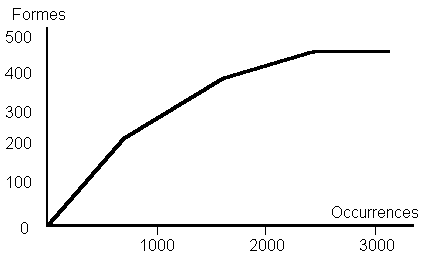|
 |
|
|
|
Résumé
Le succès du repérage
dans une base de données textuelles nécessite, encore
plus que dans une base de données bibliographiques, un
contrôle et une structuration du vocabulaire (sous quelque
forme que ce soit), rôle dévolu traditionnellement
au thésaurus. 2) L'élaboration et la gestion de ce vocabulaire sont plus complexes que pour le thésaurus traditionnel pour plusieurs raisons dont voici les principales: . la diversité et la taille des sources de données . la nature du matériau à traiter (le langage naturel)
. le nombre et la diversité
des utilisateurs potentiels . la multifonctionnalité croissante
des bases de données textuelles
À cause de la quantité,
de la diversité et de la complexité, il faut procéder
à des catégorisations qui rendent les sources et
les données lexicales plus manipulables. Il faut donc s'interroger
sur la validité des approches et des traitements traditionnels.
Des remises en question s'imposent donc: . sur le type de sources à exploiter pour la collecte des termes . sur les objets à représenter . sur le type d'unités de représentation pertinentes . sur les interrelations entre le vocabulaire du domaine et le vocabulaire général
. sur les regroupements des unités
lexicales
De nouvelles méthodologies doivent
être mises au point qui laissent l'être humain intervenir
au bon moment, mais qui l'assistent le plus possible. En annexe
sont présentées des exemples de traitements effectués
à l'aide de SATO (système d'analyse de textes par
ordinateur) pour chacune des grandes étapes de l'élaboration
et de la gestion du vocabulaire. 5) Bien que nécessaires, le contrôle et la structuration du vocabulaire sont insuffisants pour représenter adéquatement le contenu des textes.
INTRODUCTION
Pour les personnes chargées
d'élaborer et de gérer les thésaurus nécessaires
à l'indexation et à l'interrogation des bases de
données, les nouvelles technologies ont apporté
des changements importants ces dernières années.
La taille des corpus lisibles par ordinateur s'est accrue soudainement
(on parle de centaines de milliers de pages pour un seul service,
et même pour un seul projet, dans une grande entreprise).
La nature des textes s'est diversifiée: textes scientifiques,
techniques, normatifs, législatifs, correspondance, etc.
se côtoient. En outre, la langue naturelle dans laquelle
les documents sont rédigés constitue un nouveau
matériau à traiter, beaucoup plus abondant et complexe
que les représentations réduites issues du filtrage
et de la normalisation effectués par les indexeurs.
Or, le succès de l'utilisation
d'une base de données textuelles nécessite, encore
plus que pour une base de données bibliographiques, un
contrôle et une structuration du vocabulaire (sous quelque
forme que ce soit), rôle dévolu traditionnellement
au thésaurus. Mais à cause de la quantité,
de la diversité et de la complexité des données
textuelles et lexicales, l'élaboration et la gestion de
ce vocabulaire posent des problèmes particuliers qui pouvaient
passer inaperçus dans les thésaurus traditionnels.
Une fois constituées, les bases de données textuelles
peuvent être analysées et interrogées à
l'aide de l'ordinateur ou de façon automatique; de plus,
elles sont susceptibles de remplir toutes sortes de fonctions:
repérage de textes ou de passages de textes, aide à
la lecture, aide à la synthèse, aide à l'écriture,
aide à l'établissement de nomenclatures, aide à
l'élaboration de bases de connaissances, fourniture de
réponses factuelles, etc. Cette multifonctionnalité
accroÎt d'autant le nombre et la diversité des besoins
à satisfaire, puisque de nouveaux utilisateurs s'ajoutent
aux utilisateurs desservis autrefois par des systèmes bibliographiques
construits spécialement pour répondre à des
attentes relativement stéréotypées et bien
cernées. Les produits issus des opérations de collecte
et de gestion du vocabulaire sont donc susceptibles d'être
utilisés pour d'autres fins que le repérage et l'analyse
documentaires habituels. C'est pourquoi, il faut s'interroger
sur la validité des méthodes traditionnelles que
l'on pourrait souvent qualifier d' ad hoc, subjectives,
longues et coûteuses. Mais on se heurte rapidement à
un vide théorique, déploré à quelques
reprises - mais trop rarement - dans la littérature. Nous poursuivons, dans cette présentation, deux objectifs: 1) énumérer quelques-unes des remises en question qui s'imposent en ce qui concerne le contenu et la structure des thésaurus;.
2) exemplifier, en annexe, certains
éléments de méthodologie développés
pour assister l'élaboration et la gestion d'un vocabulaire
de domaine avec le logiciel SATO.
QUELQUES REMISES EN QUESTION NÉCESSAIRES
QUELLES SOURCES DE DONNÉES
PRIVILÉGIER?
Les sources documentaires
Alors que, pour construire un thésaurus
avec les méthodes traditionnelles, il fallait des mois
- voire des années -d'indexation (méthode a posteriori
), de consultation de sources de références et de
réunions d'experts pour colliger les termes du domaine
(méthode a priori), il suffit désormais de
quelques minutes ou de quelques heures, selon le volume des données
et la complexité des analyseurs employés, pour obtenir
le lexique des formes simples et des formes composées d'une
base de données textuelles. D'autres sources de données,
comme les définitions de dictionnaires ou de banques de
terminologie sont également lisibles par ordinateur. Nous
sommes confrontés à des interrogations sur la validité
de ces sources tout autant que sur la façon de les exploiter
au mieux, le débat sur les thésaurus de recherche
("search only thesaurus") conçus directement
à partir du contenu des bases de données (Bertrand-Gastaldy,
1984; Lancaster, 1977; Richer, 1986; etc.) n'ayant pas fourni
plus de fondements théoriques que les normes qui continuent
de recommander, sans véritables justifications, un mélange
des deux méthodes.
Corpus de l'organisation
Dans un contexte administratif, les
textes du corpus auxquels on veut accéder constituent en
quelque sorte les archives de l'activité de l'organisation
qui les a produits. Aussi semble-t-il normal d'extraire le vocabulaire
de ces documents et de mettre en évidence les multiples
interrelations qui se nouent et se dénouent dans les textes.
Nous avons pris le parti d'exploiter d'abord ces sources-là,
avec SATO, logiciel orienté vers l'analyse de contenu.
Pour la découverte de leurs
régularités, plusieurs théories peuvent être
mises à contribution: la linguistique descriptive, et plus
particulièrement la sémantique textuelle (Rastier,
1987, 1989), la théorie des langues de spécialité
(Grishman et Kittredge, 1986; Kittredge et Lehrberger, 1982, entre
autres).
Sur le plan pratique, nous nous sommes
posé la question de savoir comment déterminer le
moment opportun pour le dépouillement. Trois indicateurs
empruntés à la lexicométrie suffisent à
nous renseigner sur le ralentissement de la croissance du vocabulaire
au fur et à mesure dque de nouveaux documents sont insérés
dans la base: taux de renouvellement du vocabulaire, taux de répétitivité,
comportement des formes de fréquence 1,2 et 3 .
Documents de référence
Mais ces sources sont-elles suffisantes?
Les connaissances nécessaires pour accéder efficacement
à ces textes et pour les indexer sont-elles explicitement
inscrites dans ces sources? N'y a-t-il pas beaucoup de savoir
supposé connu des lecteurs qu'il faudrait aller chercher
dans les ouvrages de référence du domaine et dans
les lexiques, dictionnaires ou encyclopédies, terminologies
du domaine et autres thésaurus?
Cependant, n'y a-t-il pas retard de
ces sources et décalage par rapport au savoir contenu dans
le corpus auquel on veut donner accès? Ne révèlent-elles
pas l'idéologie d'un hyper-énonciateur, dans un
contexte donné, à un moment donné de l'évolution
du savoir, toutes circonstances qui ne sont pas identiques à
celles qui ont entouré la production des textes à
interroger?.
Les questions soulevées diffèrent
sans doute selon le contexte d'utilisation. Contrairement aux
publications scientifiques, les textes prescriptifs, législatifs
et normatifs sont en général assez explicites, à
preuve les nombreuses définitions que l'on retrouve dans
le Répertoire des Politiques du Gouvernement, les
lois, les conventions collectives et les contrats. De plus, dans
une organisation, la base de données textuelles est interrogée
par des utilisateurs qui sont souvent les créateurs des
documents; ils possèdent donc le savoir implicite nécessaire
à leur interprétation. Pour confirmer cette intuition,
il faudrait étudier à quel type de connaissances
les indexeurs et les utilisateurs recourent, lesquelles figurent
dans les thésaurus, lesquelles sont mobilisées par
les individus, selon leur formation et leurs intentions, et avec
quel succès.. Les connaissances à représenter
pour faciliter l'interrogation ne sont d'ailleurs pas les mêmes
selon que celle-ci est effectuée par l'être humain
assisté de l'ordinateur ou qu'elle est entièrement
déléguée à l'ordinateur. Connaissances
linguistiques, sémantiques et pragmatiques sont nécessaires
pour interpréter les textes et reconnaÎtre les référents
des termes. Les réflexions d'Eco (1988) sur le dictionnaire
et l'encyclopédie incitent à une révision
profonde de nos façons de concevoir le thésaurus
et son interrelation avec d'autres outils de représentation.
Par comparaison avec les questions
théoriques, les problèmes pratiques sont plus faciles
à résoudre étant donné la disponibilité
de plus en plus fréquente sur CD-ROM de ces sources et
les recherches en intelligence artificielle pour l'exploitation
des définitions (Ahlswede, 1985; Ahlswede et Evens, 1988;
Calzolari, 1988) nous ont incitées à mettre au point
une méthodologie consistant à dériver des
données du dictionnaire électronique Le Grand Robert
et à les traiter avec SATO (Houde, 1991). Les expériences
sur une banque de terminologie comme Termium se sont révélées
moins productives (Tardif, 1991), mais elles devraient être
poursuivies.
Les individus
Comme dans tout dialogue, dans la communication
avec la base de données on ne peut tenir compte d'un seul
interlocuteur. Il faut assurer la compatibilité entre les
réalisations linguistiques des textes et les pratiques
langagières des utilisateurs (par exemple, frais de
voyage employé par les fonctionnaires doit permettre
d'accéder à frais de déplacement,
seule expression figurant dans le corpus de la Politique administrative
du Gouvernement du Québec). On parle de "vocabulaire
d'entrée" à propos des termes équivalents
qui sont ainsi rajoutés. Les nouvelles technologies permettent
de détecter plus facilement les termes manquants: un module
de messages pour suggestions d'insertion de nouveaux termes peut
être mis à la disposition des utilisateurs ou bien
les stratégies d'interrogation peuvent être enregistrées
systématiquement (ainsi, pour conserver la trace de l'interaction
avec le corpus, il suffit de se mettre en mode témoin dans
le module SATOINT de SATO). Ensuite, il faut analyser les données
recueillies. Güntzer et al. (1988) propose un système
d'apprentissage à partir des questions: TEGEN (thesaurus
generating system) qui non seulement construit progressivement
des regroupements de termes, mais qualifie les relations lexico-sémantiques
sur la base des opérateurs logiques employés dans
les stratégies, de vérifications et de dialogue
avec les utilisateurs.
QUELS TYPES DE SIGNIFIANTS RETENIR
DANS UN THÉSAURUS?
Les signifiants et les signifiés
Comme on traite du texte avec tous
les systèmes (morphologiques, lexicaux, sémantiques,
textuels et intertextuels) qui s'interrelient pour produire du
sens, il faut bien distinguer ce que l'on manipule: signifiants,
signifiés et attributs des uns et des autres aux différents
niveaux.
Parmi les signifiants, on peut relever
les morphèmes, les formes simples, les lexies simples ou
complexes, les termes, les noms propres, les énoncés,
le texte dans son entier, etc. Les signifiés diffèrent
selon la nature des signifiants: sèmes, concepts, actions,
propriétés, (Aitchison et Gilchrist, 1987; Pavel,
1989: 349), propositions et discours du texte au sens où
Meunier l'enttend (1990). Quant aux référents, ce
peut être des objets, des individus, des événements.
L'intérêt de cette distinction
est double:
1) On distingue mieux les opérations
à effectuer, sur quels objets elles portent , quelles propriétés
elles confèrent et selon quels principes on peut regrouper
les objets Par exemple: - Reconnaissance des caractères et segmentation en chaÎnes de caractères, phrases et paragraphes; édition du lexique des formes; - Analyse morpho-syntaxique des occurrences pour l'obtention de lexèmes simples ou complexes, de préfixes, suffixes, radicaux avec possibilité de regroupement par familles de mots; - Analyse lexico-sémantique des lexèmes pour la représentation de relations; - Analyse sémantico-pragmatique pour le choix des termes du domaine et l'établissement de relations entre termes et lexèmes ainsi que pour la représentation des concepts avec leurs traits;
- Analyse syntaxico-sémantique
des énoncés pour la représentation, sous
forme normalisée, des termes et du rôle qu'ils occupent
(action, agent de l'action, objet ou patient de l'action, etc.)
2) On distingue mieux les propriétés et attributs attachés à chaque objet En interrogeant la base de données, on pourra alors répondre avec précision à des questions de ce genre: - Quelle est la fréquence de la forme singulière de "peuple", de sa forme plurielle? du lexème "peuple"? des dérivés comme "dépeuplement"? - Quelles sont les valeurs de catégorie grammaticale réalisées dans le corpus pour la forme or ? Est-il toujours conjonction de coordination, ou le retrouve-t-on comme substantif? - Quelle est la fréquence du concept si, dans le corpus, "foule", "citoyen" etc. sont considérés comme synonymes? - Depuis quand tel ou tel lexème est-il attesté dans le corpus? - À quelle époque tel ou tel concept est-il apparu, si l'on tient compte des périphrases attestées avant qu'un terme soit adopté par la communauté? - Depuis quand le système d'indexation a-t-il opté pour tel descripteur au détriment de tel autre pour représenter tel concept? - Comment a évolué le concept de déchet, dans les dix dernières années? Quelles propriétés (ou traits de substance, selon Le Guern, 1989) lui a-t-on attribuées au fil du temps? - Quelle est la composition d'un produit chimique? Quelles sont ses utilisations médicales? - Quels sont les verbes que l'on retrouve le plus souvent associés avec tel ou tel terme du domaine? - Ce terme figure-t-il exclusivement dans un rôle d'agent par rapport à cette action? Ou bien peut-il occuper le rôle de patient? - Quelle est la fréquence d'emploi de tel ou tel lexème dans la macro-structure des textes (titres et sous-titres)? Est-il plus souvent présent au niveau de la micro-structure? - D'après le contenu du corpus, peut-on dire que tel terme est un spécifique de tel autre?
- Quels sont les individus auxquels
les textes font référence, selon quelles désignations?
On peut ainsi concevoir une base de
concepts, une nomenclature d'objets concrets contenant les propriétés
de chacun d'eux et une base de termes dont certains peuvent renvoyer
au même concept ou au même objet, parce qu'ils sont
synonymes ou équivalents dans des langues différentes.
Ainsi la base de termes devient un sous-ensemble du lexique et
des interrelations entre les deux entités peuvent être
mises en évidence. On notera au passage que si le nom propre
n'a de référence qu'individuelle, un nom commun
peut renvoyer à un concept et à une réalité
désignée (Lerat, 1983), ce que la littérature
sur les thésaurus se garde bien de préciser, comme
elle escamote d'ailleurs la définition du concept et la
question de la différence entre un terme complexe et un
énoncé.
Du lexique d'un corpus aux termes
du domaine: lexèmes complexes et termes
Toutes les unités lexicales
ne sont pas utiles pour exprimer les notions du domaine. Il faut
connaÎtre le domaine pour pouvoir se prononcer sur la probabilité
qu'un lexème soit un terme. La collecte et le choix des termes du domaine à partir des corpus posent deux problèmes principaux: - l'extraction des lexies complexes, puisque beaucoup de termes sont des nominations syntagmatiques.
- la détermination de critères
aussi objectifs que possible pour retenir seulement les termes
du domaine, parmi les lexèmes simples et complexes .
Il s'agit là de deux opérations
très complexes, qui constituent souvent un goulot d'étranglement
et pour lesquelles les normes et manuels, conçus dans une
perspective de sélection par l'être humain, ne sont
pas d'un grand secours. Elles doivent être formalisables,
au moins pour la partie du travail que l'on veut confier à
l'ordinateur.
Pour la première étape,
l'extraction des lexies complexes, un analyseur morpho-syntaxique
comme il en existe dans Termino, serait sans doute nécessaire.
Au moins deux obstacles s'opposent pour le moment, au recours
généralisé à un logiciel de ce genre:
la taille des corpus et la particularité de la syntaxe
de certains domaines de spécialité par rapport à
la syntaxe de la langue courante. La procédure MARQTERM
qui a été mise au point avec SATO s'appuie sur l'existence
de bases de données lexicales dans lesquelles les formes
sont affectées de toutes les valeurs de catégorie
grammaticale qu'elles peuvent avoir hors contexte et sur la recherche
dans les textes de séquences de valeurs comme: nom + adjectif
(politique administrative, conditions météorologiques),
Nom +préposition +nom (concours de recrutement, eau
de transplantation ), adjectif + nom + adjectif ( grand
ensemble urbain, hautes eaux printanières ), etc. Ce
procédé, plus bruyant que le premier, peut être
appliqué avec plusieurs variantes selon le degré
d'exhaustivité recherché; il est indépendant
de la langue et peut servir à découvrir des configurations
d'expressions complexes propres à un discours donné.
Quelle que soit la stratégie
adoptée, il faut faire un tri.
Citons d'abord, parmi les problèmes
non résolus, la décision de garder une expression
complexe telle quelle ou de la décomposer en ses expressions
minimales. La norme ISO 2788 (1986) sur les thésaurus monolingues
fournit quelques règles, sans les justifier de façon
rigoureuse, en omettant des configurations syntaxiques fréquentes
et en faisant abstraction des dimensions socio-cognitives. Elle
est orientée vers la collecte de termes minimaux en vue
de la représentation d'énoncés complexes
basée sur la grammaire des cas. Ses recommandations sont
très fortement inspirées du système PRECIS
(Preserved Context Indexing System): action, objet de l'action,
agent de l'action, lieu de l'action, etc.) et ne sont d'aucun
secours pour régler des cas comme abus de pouvoir ,
abus du pouvoir ; voyage présidentiel , voyage du président,
etc.
Ensuite, toutes les lexies complexes
retenues ne traduisent pas des objets (concrets ou abstraits)
propres au domaine. Comme le soulignent David et Plante (1990),
l'unité terminologique n'est pas un pur fait de langue,
elle appartient à un système cohérent, énumératif
et/ou structuré, chargé de représenter un
domaine de connaissances. Elle fait intervenir les pratiques socio-culturelles
d'une communauté et des caractéristiques d'ordre
psychologique. Pour en tenir compte, il convient de scruter avec
soin les réalisations linguistiques du corpus, de considérer
la fréquence de certains regoupements, leurs caractéristiques
éditoriales (position dans le corpus, typographie, etc.),
la mobilité de chacun des éléments entrant
dans une expression complexe afin d'en déterminer le degré
de figement (Gross, 1988) et,.bien sûr, de recourir à
l'avis des experts. Nous avons profité de la souplesse
de SATO pour développer quelques procédures qui
favorisent la prise de décision: affichage de plusieurs
propriétés simultanément, pondération
en fonction de certaines de ces propriétés, classement
selon un ordre décroissant de pertinence probable et enregistrement
des avis des experts qui, ultimement, se prononcent sur l'appartenance
ou non au domaine (Paquin et al., 1990:.104)
Il est probable qu'un thésaurus
conçu pour l'indexation et le repérage assistés
par ordinateur doive contenir des unités de représentation
très différentes d'un thésaurus conçu
pour une utilisation par un expert humain. Il devrait sans doute
offrir des expressions "à géométrie
variable", c'est-à-dire plus ou moins précoordonnées.
L'affichage du contexte sous forme d'index KWIC rend tout lexème
simple accessible quelle que soit sa position dans un terme complexe.
Comme, en outre, il faut permettre aux utilisateurs de connaÎtre
le plus exhaustivement possible les configurations présentes
dans le corpus et comme l'usage évolue, il vaut sans doute
mieux ne pas imposer de règles artificielles de décomposition
et refléter le contenu réel de la base de données.
D'autres modes de visualisation devraient être développés
pour permettre de considérer le vocabulaire "sous
toutes ses coutures", en contexte et hors contexte.
La catégorie syntaxique des
unités lexicales nécessaires pour la représentation
des énoncés
Le traitement de corpus en langue naturelle
oblige à remettre en question la nature syntaxique des
unités linguistiques qui constituent habituellement les
thésaurus. Peut-on continuer de se restreindre aux nominaux?
Pourquoi ne pas inclure les verbes, les adverbes et les adjectifs?
Il faut se demander quelle est la fonction des catégories
syntaxiques dans la représentation des concepts et des
propositions.
Plusieurs arguments militent en faveur
de l'inclusion:
- Les catégories de mots généralement
exclues ont des fonctions importantes équivalentes aux
catégories de termes "autorisées". . Actions: noms ou verbes Extraction, extraire . Attributs des actions: adjectifs ou adverbes Extraction automatique, extraire automatiquement . Objets: sol . Attributs des objets: adjectifs ou noms sol humide, humidité du sol
Dans le premier de ces exemples, le
focus est sur l'objet, tandis que dans le second, il est sur l'attribut.
-Tout n'est pas substantivable, comme
le montrent ces exemples: information (nom) informatif (adjectif) informer (verbe) presse (nom) 0 0
0 social 0
L'adjectif est un des éléments
qui modifient le substantif. Quant au verbe, il exprime dynamisme
et temporalité. Comme le fait remarquer Garcia Guitiérrez
(1990), il sert de régulateur du sens des énoncés
documentaires normalisés dans lesquels il introduit des
prépositions directionnelles (que l'on appelle des opérateurs
de rôle dans les langages documentaires). De même,
pour retrouver des notions dans les bases de données en
plein texte, il faut disposer d'outils qui permettent d'accéder
à plusieurs formulations possibles, car elles ne sont pas
toujours exprimées sous forme nominale.
Vocabulaire général,
vocabulaire de domaine et co-occurrents
Gémar (1991) parle de trois
sous-ensembles du vocabulaire: le vocabulaire général,
la terminologie du domaine et les co-occurrents des termes, c'est-à-dire
les verbes ou les adjectifs qui reviennent le plus souvent avec
tel ou tel terme. La question, pour les concepteurs de thésaurus,
est de savoir où faire figurer ces co-occurrents. Faut-il
les placer dans les thésaurus, bien qu'ils ne soient pas
propres au domaine? Il convient de réfléchir à
l'interrelation entre le lexique et le thésaurus. Plus
fondamentalement, il faut revoir la fonction du thésaurus
dans le contexte nouveau du plein texte.
LES REGROUPEMENTS DES UNITÉS
LEXICALES
La diversification et le nombre des
objets à inclure ne font qu'accroÎtre le besoin de
regroupement pour faciliter l'ordre et la cohérence. Il
faut en effet fournir des connaissances sur le vocabulaire et
les concepts, afin de faciliter l'établissement des stratégies
de recherche et l'obtention de taux de rappel et de précision
optimales. La catégorisation en vue de regoupements a toujours
existé en documentation. Il est intéressant d'observer
que les terminologues s'en préoccupent de plus en plus,
pour les mêmes raisons: "Toutes sortes de relations implicites entre les termes se retrouvent au hasard dans la définition. Ainsi pour le traducteur, le domaine en question est morcelé, chaque définition donne un aperçu fragmentaire du domaine. C'est un peu comme un puzzle qu'on n'arrive pas à assembler parce qu'il y a des pièces qui manquent, et qu'on n'a pas l'image de l'ensemble qui devrait servir de guide.
Nous sommes amenés à
conclure qu'on a besoin d'une organisation conceptuelle qui permette
à l'usager du dictionnaire de reconstruire, à partir
de ses éléments constitutifs, une image cohérente
du domaine. " (Kukulska-Hulme et Howles, 1989: 382)
Nous allons passer en revue quelques
regroupements possibles, sans nous limiter à ceux que l'on
trouve habituellement dans les thésaurus.
Les regroupements lexicaux
La réduction des formes du langage
naturel est nécessaire pour contrer la dispersion de l'information
sous différentes "étiquettes"; elle s'effectue
au moyen de regroupements, dont le plus connu est le contrôle
orthographique (clé et clef; BNQ
et Bibliothèque nationale du Québec ). D'autres
sont nécessaires.
Regroupements des variantes flexionnelles
Dans un thésaurus traditionnel,
on n'inscrit que la forme lemmatisée des termes retenus
pour représenter le contenu des documents et, comme cette
convention est connue des utilisateurs, aucun renvoi n'est effectué.
Dans le cas des textes en langue naturelle,
une analyse morpho-syntaxique devrait permettre de regrouper automatiquement,
si cela est nécessaire aux besoins de repérage,
les différentes variantes flexionnelles d'un lexème.
C'est l'opération de lemmatisation qui permet de ramener
les verbes à l'infinitif, les substantifs au singulier,
les adjectifs au masculin singulier et les formes élidées
à la forme sans élision: plantureux | plantureuse |_________ plantureux
plantureuses |
veuillez | veut |_________ vouloir voudront | voulons |
etc.
Étant donné que la consultation
d'un corpus textuel peut avoir des objectifs fort diversifiés,
comme la vérification de la fréquence du pluriel
par rapport au singulier ou bien la recherche de l'expression
du futur ou du passé, la lemmatisation devrait toujours
être offerte en option seulement. Précisons qu'elle
n'est pas disponible dans SATO et que le recours aux opérateurs
de troncature et au masque n'est qu'un palliatif. Il faut réviser
le travail et procéder aux regroupements grâce à
une propriété comme Lemme.
Regroupement morpho-lexical des
dérivés et des composés autour d'un radical
commun
Une même idée peut être
exprimée par des combinaisons multiples de différentes
catégories grammaticales de mots. Le contrôle lexical
offre un moyen de contourner en partie le problème de la
variété syntaxique au niveau de la phrase. En effet,
si la synonymie phrastique permet d'éviter les répétitions,
tout comme la synonymie lexicale, elle a des conséquences
fâcheuses pour l'exhaustivité du repérage
de l'information.
Par exemple, dans un corpus en environnement,
on trouve amélioration des normes de pollution ,
amélioration du rendement du traitement , mais pas
amélioration de la précipitation du cadmium,
notion pourtant présente dans la phrase suivante:
La précipitation du
cadmium peut être améliorée
parl'addition d' hydroxyde de sulfure.
Autre exemple: récupération
de nickel et récupération des ions métalliques
figurent tels quels, mais pas récupération du
cadmium exprimé ainsi:
La technologie de la précipitation
permet de récupérer
le cadmium sous forme de précipités
d'hydroxyde, de carbonates ou de sulfures non solubles.
Ces exemples confirment l'importance,
aussi bien pour le repérage que pour l'indexation, d'une
part de répertorier les termes simples susceptibles d'entrer
dans la composition d'un terme complexe, d'autre part d'effectuer
des regroupements de lexèmes formés autour d'un
même radical. Il faut cependant prendre garde que si un
nom d'action est l'équivalent d'un verbe d'action, il n'est
pas l'équivalent d'un adjectif exprimant l'état.
Ainsi récupération des métaux n'est
pas synonyme de métaux récupérés
: dans le premier cas, l'accent (on dit parfois le focus) est
mis sur l'action, dans le second sur l'objet issu de l'action.
De même, bien que toxicité et toxique
soient tous deux des attributs, un segment de texte qui traite
de toxicité des métaux n'est pas équivalent
à un segment qui traite des métaux toxiques.
Dans le premier cas, l'attribut peut lui-même avoir des
attributs (la toxicité des métaux est dangereuse
), dans le second c'est l'entité métaux toxiques
qui peut avoir des attributs (les métaux toxiques sont
dangereux ). C'est pourquoi l'adjectif et le nom ne peuvent
être synonymes. Les adjectifs modifient les noms et établissent
ainsi des sous-classes de termes spécifiques par rapport
aux termes simples. Autour de -plant-, on pourra regrouper : planter plants transplant transplants transplanter transplantation replanter
etc.
Le regroupement n'est cependant pas
toujours aussi facile, car ou bien le radical a subi des modifications
ou bien il se présente sous des formes différentes
selon qu'il est pris dans un mot latin ou grec ou dans un mot
français, ou encore il est de formation savante et populaire,
comme le montrent les exemples suivants empruntés à
Ménard (1989): voir/ visiblement lumière/lumineux, luminosité
caprin/chevrotant
On fait également face à
"des cas de dérivations multiples qui s'accompagnent
de différenciations sémantiques importantes, comme
celles qui se sont opérées entre receveur
et récepteur , parlement et parloir
, etc." (Lerat, 1984: 23). Les regroupements ne peuvent donc
pas être effectués de façon entièrement
automatique, sous peine de nuire à la précision
du repérage.
Établissement de classes
"fondamentales" ou facettes
Onpeut également regrouper les
termes par facettes, selon une caractéristique fondamentale
qui les distingue des termes des autres classes: Actions/processus améliorer amélioration précipiter précipitation
récupérer récupération
Entités cadmium cuivre ion, ions ion métallique, ions métalliques mercure métal, métaux
précipité, précipités
Attributs . Qualificatifs
toxique, toxiques . Noms de qualités concrètes ou abstraites
toxicité
Les suffixes peuvent être utilisés
pour ce type de regroupements en facettes ou sous-facettes. Des
troncatures judicieuses rendent l'opération possible en
l'espace de quelques minutes; il faut, bien sûr, réviser
les listes obtenues, pour que table ne soit pas rangé
parmi les attributs au même titre que potable , par
exemple. Les suffixes comme -ture, -tion, -aison, -ie, -age, etc. forment des noms d'actions ou de processus. On cherchera la forme verbale correspondante: comparaison comparer cadrage cadrer copie copier saisie saisir instauration instaurer piégeage piéger amélioration améliorer application appliquer augmentation augmenter
contamination contaminer Kukulska-Hulme et Howles (1989) fournissent d'autres exemples, comme les verbes dénominaux, pour les actions: arboriser complexifier
modulariser
Dans certains corpus, on détectera
facilement des termes de maladies se terminant par -ose
(fibrose, nécrose, lordose ). Les agents humains pourront être cherchés avec des suffixes comme -eur (employeur, coiffeur ) et -euse (coiffeuse), -iste (machiniste ), -ateur (formateur ) et -atrice, -ier (policier) et
-ière
(infirmière
), -icien (cogniticien, informaticien ), etc.
Des substantifs se terminant en -itude
(similitude, amplitude, magnitude), en -ité
(vélocité, actualité, humidité
), etc. et des qualificatifs en -if (actif, exclusif,
cumulatif ) donneront lieu à des classes de termes
indiquant des propriétés.
À ce niveau, il s'agit donc
de disposer avant tout de capacités de fouille pour détecter
les catégories prédominantes dans le corpus et de
possibilités pour catégoriser les unités
repérées.
Les relations de synonymie et
d'antonymie
Les relations de synonymie et d'antonymie
sont plus coûteuses à inclure que les relations entre
variantes morpho-lexicales, puisque, reposant sur des connaissances
sémantiques et pragmatiques, elles nécessitent un
investissement humain. Mais les auteurs sont unanimes à
les considérer comme rentables pour l'interrogation.
La synonymie et l'antonymie sont réglées
par une seule et même relation, la relation d'équivalence,
dans les thésaurus traditionnels. Dans la mesure où
le système d'indexation et de repérage repose en
partie sur des inférences faites automatiquement, il peut
être nécessaire de conserver plus de finesse, d'autant
plus que, d'après Wang et al. (1985), l'inclusion
d'antonymes lors de l'interrogation d'une base de données
textuelles entraÎne une très nette baisse du taux
de précision.
La sémantique lexicale fournit
d'amples explications sur la synonymie hors contexte et en contexte,
la synonymie absolue et la synonymie partielle, de même
que sur les différents types d'antonymes: paires opposées
comme vente et achat , paires complémentaires
comme poule et coq , éléments d'une
gradation: grand , moyen et petit.
Outre le choix du degré de finesse
en fonction du contexte d'utilisation, se pose le problème
de la détermination des synonymes et antonymes dans le
domaine particulier représenté dans la base de données,
et non pas dans la langue générale. En complément
de la consultation d'experts, toujours longue, on a intérêt
à fouiller le corpus qui contient des formules (par exemple
des formes fonctionnelles: comme, ou, soit, et ) susceptibles
de traduire de telles relations. C'est un apport original de logiciels
qui , comme SATO, sont orientés vers l'analyse de contenu,
contrairement aux logiciels documentaires. La détection
des relations hiérarchiques, de même que la recherche
des définitions de termes bénéficient d'ailleurs
de la même approche.
Les relations hiérarchiques
Dans les thésaurus traditionnels,
les relations hiérarchiques recouvrent les relations génériques,
les relations d'instanciation et les relations partitives. Chacune
d'entre elles devrait être subdivisée en de nombreuses
autres dans les systèmes qui fonctionnent par inférence.
En effet, pour un repérage efficace, si l'élargissement
ou le rétrécissement des stratégies de recherche
se fait par consultation automatique du thésaurus, les
relations d'inclusion (relations genre/espèce et simples
relations spatiales) doivent être distinguées des
relations partitives ainsi que des relations de possession et
des relations qui expriment les attributs. En intelligence artificielle,
il existe des mises en garde contre le risque de confusion entourant
la relation IS-A (Brachman, 1982) assimilable à la relation
hiérarchique.
Pour les relations génériques,
on peut procéder à un premier regroupement autour
d'une tête de syntagmes à partir des déterminations
nominales, de façon à obtenir un paradigme. Ghazi
cité par Nakos (1989: 354) donne cet exemple: néphrite | __|__ | | | | néphrite aiguë néphrite chronique | | néphrite chronique atrophique | |
néphrite chronique atrophique
de l'enfance
Une structuration poussée nécessite
une connaissance approfondie des traits qui caractérisent
chaque concept. La détermination nominale peut, en effet,
être trompeuse car on observe une tendance à la réduction
des termes complexes qui contiennent la trace de ces traits, réduction
qui se fait par siglaison ou acronymie comme dans CAO
pour conception assistée par ordinateur, ou encore
par télescopage comme dans infotecture pour informatique
et architecture (Nakos, 1989: 355-356). Lethuillier (1989:
446) dénonce, lui aussi, la fausse transparence des termes.
La littérature conseille, pour
la clarté de la présentation, d'introduire dans
la hiérarchie un relais virtuel (ou indicateur de facette)
qui indique quelle caractéristique a été
utilisée pour diviser une classe (représentée
par un terme générique) en ses différents
types de spécifiques. C'est la seule occasion où
l'on fait référence à la représentation
des traits des concepts et, encore, on les met comme entre parenthèses,
on parle de relais virtuel. C'est pour le moins étonnant,
dans un outil qui est censé représenter les concepts
d'un domaine!
Ainsi à partir d'une liste alphabétique
non structurée comme celle-ci: Congé Congé à temps plein Congé à traitement différé Congé de maladie Congé de préretraite Congé de maternité Congé hebdomadaire Congé partiel Congé pour adoption Congé pour affaires judiciaires Congé pour événements familiaux Congé pour responsabilités parentales Congé sabbatique
Congé sans traitement
on peut obtenir des sous-ensembles
regroupant les concepts par une de leurs caractéristiques
communes. Le choix des caractéristiques se fait de façon
empirique, d'après la liste des termes recueillis dans
le corpus: . Selon le motif: Congé pour affaires judiciaires Congé pour événements familiaux Congé de préretraite Congé de maladie Congé de maternité Congé pour adoption Congé pour responsabilités parentales
. Selon la fréquence: Congé hebdomadaire
Congé sabbatique . Selon les conditions de rémunération: Congé à traitement différé
Congé sans traitement . Selon la "complétude": Congé à temps plein
Congé partiel Des termes spécifiques peuvent provenir d'une combinaison de caractéristiques:
Congé partiel sans traitement
Il existe de nombreux types de relations
partitives (méronymiques) qui ont été
scrutés par Winston et al. (1987). Elles incluent
le composant d'un objet, le membre d'une collection, la portion
d'une masse, le matériau qui entre dans la composition
d'un objet, une sous-activité d'une activité composite,
l'endroit qui fait partie d'un lieu. Ce serait donc par une de
ces relations partitives que l'on pourrait exprimer une suite
chronologique d'événements, les étapes d'un
projet d'évaluation environnementale, par exemple, qui
comprend, entre autres, le dépôt de l'avis de projet,
l'élaboration de la directive, la réalisation de
l'étude d'impact, son dépôt, la consultation
par le public, la tenue d'une audience publique, etc. jusqu'à
la surveillance et au suivi si le projet est accepté et
réalisé. Le thésaurus relationnel de Wang
et al. (1985) compte sept types de relations partitives.
Même si l'analyse de contenu
assistée permet de repérer des relations hiérarchiques
et, dans plusieurs cas, de distinguer entre certains types de
relations (partie de, membre de, etc.), dans les corpus
et dans les sources lexicologiques ou terminologiques, une sérieuse
réflexion s'impose sur les conditions préalables
à des regroupements homogènes.
Les relations associatives
Les relations associatives dans les
thésaurus sont un véritable fourre-tout, on le sait.
Outre le fait qu'on peut trouver des
relations entre termes de sens voisin, on constate que le type
de relations admises par la norme regroupe des relations de co-occurrence
entre deux termes entretenant dans les énoncés textuels
d'abord des relations syntaxico-sémantiques autour d'une
action implicite (agent de l'action - objet ou patient de l'action
- instrument de l'action, etc.), ensuite des relations entre désignation
du concept et propriétés du concept., enfin des
relations entre déterminé et déterminant
du type Permis d'absence -- Absence .
Regroupements automatiques
On peut se demander, dans ces conditions,
si des relations associatives aussi nombreuses et disparates établies
bien souvent sans grande systématicité par les concepteurs
de thésaurus ne gagneraient pas à être dérivées
des textes par une simple analyse de co-occurrence dans un contexte
déterminé, celui de la phrase dans lequel on peut
retrouver les trois catégories de relations que nous venons
d'énumérer. À défaut d'être
spécifique, cette solution garantirait une plus grande
objectivité et une plus grande fidélité dans
la représentation du corpus, pour peu qu'une mise à
jour périodique soit assurée. De telles relations
devraient être élaborées a posteriori
suite à une analyse statistique du corpus, plutôt
qu'a priori sur la base du "corpus virtuel"
(de la structure cognitive) du concepteur de thésaurus.
Ainsi, d'après Hutchins (1975: 48), on associera dans un
thésaurus les termes délinquance juvénile
et hostilité , parce que ces deux termes ont une
co-occurrence élevée dans un corpus documentaire,
ou bien comme on l'a constaté il y a quelques années
dans un thésaurus en éducation, entre analphabétisme
et haïtiens.
La méthode de regroupement la
plus attrayante à cause de sa facilité de mise en
oeuvre, de son objectivité et de son caractère reproductible
réside dans les regroupements de formes ou de lexèmes
effectués de façon automatique. Les travaux en classification
automatique de Salton (1971), Sparck Jones (1971) sont célèbres
et connaissent un regain de popularité avec les machines
parallèles. Selon Pomian (1990), l'analyse statistique
permet de passer de données brutes à des données
structurées susceptibles d'interprétation. Elle
fait ressortir une dimension cachée, construite de l'extérieur
et projetée sur une entité préexistante.
Certains mots, certaines associations de mots apparaissent plus
fréquemment que d'autres; cela indique des structures associatives
privilégiées, donne des indications sur les contextes
de leur apparition et sur les sujets qui organisent les intérêts
des personnes. Avec le logiciel SATO, il est possible d'extraire
les termes qui co-occurrent dans un contexte spécifié
à volonté: distance de n mots, phrase, paragraphe,
chapitre, etc., car, alors la nature des relations diffère,
comme l'avait fait remarquer Moskovich (1977), puis d'exporter
les données vers un logiciel d'analyse statistique comme
SPSS pour les soumettre à des algorithmes de classification
automatique. Voici un exemple de mots (noms communs, adjectifs ou verbes) co-occurrant fréquemment avec aménagement (placé en tête de liste) dans un corpus en environnement: 20 aménagement 16 schéma 5 contrôle
5 règlement
La nature précise des relations
qui unissent ces mots peut être très diverse et seul
un spécialiste pourra distinguer ce qui est relation collocationnelle
de ce qui est relation hiérarchique, etc. Tout dépend
de ce qui, dans le discours, marque explicitement les relations
(prépositions, ponctuation, ordre des mots, etc.) et se
trouve déconstruit dans le lexique.
Si la recherche de cooccurrents s'effectue
sur des données dotées de propriétés,
grammaticales par exemple, il est probable que les regroupements
seront plus signifiants. La comparaison du lexique d'un corpus
(ou d'une partie de corpus) avec celui d'un autre corpus (ou d'une
autre partie de corpus) peut révéler des séries
de noms, d'adjectifs, de verbes caractéristiques qui, de
plus, ont une fonction syntaxique particulière (certains
verbes co-occurrent avec certains noms uniquement quand ils sont
sujets et avec d'autres noms en position d'objets). Les domaines
scientifiques et techniques présentent en général
de ces régularités propres à ce qu'on appelle
un langage de spécialité. Hirschman et al.
(1975), par exemple, a réussi à regrouper, d'après
l'analyse syntaxique de la littérature en pharmacologie,
les termes dans les classes suivantes: parties du corps humain,
patients, symptômes, analyses de laboratoire, temps, lieu,
etc. Comme l'a expérimenté Cossette (1991) sous
notre direction, un examen de quelques rapports d'analyse environnementale
du ministère de l'Environnement dans les parties consacrées
aux impacts et aux mesures de mitigation permet de dégager
les actions posées (perturbation, dérangement,
modification, etc.) qui génèrent (causer,
entraÎner, etc.) des conséquences (accroissement,
émettre, subir, etc.) soigneusement estimées
quant à l'étendue et à l'intensité
(majeur, moyen, etc.) sur un objet (habitat, résidence,
, etc.) dans un contexte précis (automne, printemps,
etc.). Il s'ensuit des actions pour atténuer les impacts.
Il va sans dire qu'une exploration aussi fine des corpus nécessite
des analyseurs linguistiques et textuels qui dépassent
de loin ce que les logiciels documentaires offrent actuellement
ou bien elle peut être effectuée par l'expert assisté
de l'ordinateur.
L'utilité des relations de co-occurrence
non étiquetées n'est pas la même selon le
contexte d'utilisation: si c'est un agent cognitif humain, il
sera capable de faire un tri parmi toutes les suggestions du thésaurus,
selon la nature réelle des relations que le rapprochement
pur et simple de deux termes lui suggère. Par contre un
logiciel de consultation n'aura pas ce savoir implicite. C'est
pourquoi des auteurs conseillent de distinguer les différents
opérateurs de ces relations de co-occurrence, surtout dans
le contexte de la consultation automatique des thésaurus
pour l'indexation ou l'interrogation. L'élargissement automatique
des stratégies de recherche par toutes sortes de liens
associatifs disparates nuit à la précision, comme
l'a montré une expérience de Rada et Barlow
(1991).
Collocations et unités lexicales
complexes
La structuration par facettes favorise
l'établissement de principes clairs pour l'établissement
de liens associatifs entre termes appartenant à des hiérarchies
différentes. Ces liens sont en fait ceux que privilégie
une communauté linguistique donnée et l'on rejoint
ici les unités lexicales complexes ou expressions en voie
de figement dont nous avons parlé plus haut.
Selon le point de vue, ces unités
lexicales complexes sont, en effet, traitées soit comme
des relations entre unités lexicales simples (Calzolari,
1988, entre autres) soit comme des lexèmes plus ou moins
figés, comme des collocations "lexicalisées"
"considérées par les locuteurs natifs comme
étant des "produits semi-finis" de leur langue":
"Les collocations ont un caractère
conventionnel à l'intérieur d'une communauté
linguistique; c'est aussi vrai pour les "microcommunautés
linguistiques" que sont les entreprises, les groupes professionnels,
etc: comme on peut observer des différences terminologiques
d'entreprise à entreprise, ou entre le langage des ouvriers
et celui des ingénieurs ou du marketing, les collocations
peuvent aussi varier selon le groupe, le registre, etc."
(Heid et Freibott,1991:79)
L'intérêt des terminologues
pour les collocations est récent, de même que la
prise en compte de la fonction terminologique des verbes; c'est
la conséquence de l'influence des dépouillements
de textes par ordinateur. Un nouveau domaine de recherche est
apparu: la "phraséologie des langues de spécialité",
(Heid et Freibott,1991: 84). On assiste à la publication
de lexiques de co-occurrents. En terminologie, Kukulska -Hulme
et Howles (1989)préconisent non seulement une catégorisation
des lexèmes en objets, actions, et attributs des objets
et des actions (approche analystique), mais aussi une représentation
des diverses combinaisons attestées dans le domaine (approche
synthétique): coût [propriété1] coût de fonctionnement [propriété1 + action1] coût d'élimination [propriété1 + action2] coût d'élimination des rejets [propriété1 + action2+ objet1]
coût d'évacuation des
rejets [propriété1
+ action3 + objet1]
La même évolution risque
bien de se dessiner pour le thésaurus. Ainsi structuré,
il dirigerait les utilisateurs vers l'élaboration de stratégies
de recherche spécifiques ou élargies, à partir
de réalisations attestées dans le corpus. Il serait
également fort utile pour l'aide à la rédaction.
En documentation, l'idée est loin d'être nouvelle,
comme les personnes familières avec les systèmes
analytico-synthétiques tels que PRECIS le savent, mais
les deux types de représentation figurent dans des outils
différents: les unités lexicales minimales dans
les thésaurus et les combinaisons collocationnelles dans
les index. Cela peut également apporter un éclairage
nouveau à la confusion qui a toujours existé à
propos de certaines relations associatives à mi-chemin
entre les relations thésaurales et les relations syntagmatiques
inscrites dans les index.
La proposition répond aux besoins
de flexibilité, d'accessibilité et de fidélité
des représentations, tout en garantissant l'ordre:
"Le dictionnaire proposé
permet donc de voir les données terminologiques de plusieurs
points de vue. Par exemple, on peut regarder les attributs des
objets tout seuls, les objets tout seuls, les objets avec leurs
attributs, les attributs avec leurs objets et ainsi de suite ...
Cela fait dix possibilités au total [...] " (Kukulska
-Hulme et Howles, 1989: 387)
"[...] la solution est intéressante,
car elle est à la fois complexe et simple. À un
certain niveau, ce ne sont que des substantifs, des verbes, des
adjectifs et des adverbes, tous prêts à être
utilisés dans la traduction. À un niveau plus approfondi,
c'est une description cohérente du domaine." (Ibid.:
389)
QUELQUES QUESTIONNEMENTS SUPPLÉMENTAIRES
SUR LES REGROUPEMENTS
Avec les regroupements, se pose tout
le problème de la catégorisation et, par conséquent,
des caractéristiques retenues pour subdiviser une liste
de termes.
UNIVERSALITÉ ET PÉRENNITÉ
DES RELATIONS
La norme ISO 2788 (1986:1) parle de
relations a priori à propos des relations figurant
dans les thésaurus, par opposition aux relations a posteriori
destinées à représenter les relations faites
dans un texte pour exprimer un sujet complexe. Elle ajoute que
les relations thésaurales "sont indépendantes
des documents puisqu'elles sont généralement reconnues
et peuvent être établies par référence
à des travaux standards tels que dictionnaires ou encyclopédies."
On peut se demander, d'une part, s'il
existe bien des relations a priori, indépendantes
du contexte, naturelles en quelque sorte, d'autre part en quoi
un thésaurus pour l'indexation et le repérage dans
un corpus textuel est utile s'il ne fait que retranscrire les
relations déjà exprimées dans les dictionnaires
de langue ou des encyclopédies.
Un terme peut, en effet, appartenir
à plusieurs catégories, selon le point de vue adopté.
Il n'existe pas à proprement parler de catégories
a priori, mais des catégories imposées par
des agents cognitifs, les auteurs des textes et reconnues par
d'autres agents cognitifs, les lecteurs, les utilisateurs. Toute
sémantique ne dépend-elle pas du contexte d'utilisation?
Frohmann (1983) l'affirme et donne l'exemple d'une liste de cinq
mots (chien, chat, baleine, brochet, hibou ) que
l'on peut subdiviser de plusieurs manières selon la caractéristique
retenue: 1er principe de subdivision: nocturne/diurne: groupe 1: chat, hibou
groupe 2: chien, baleine, brochet
2ème principe de subdivision: mammifères/non-mammifères groupe 1: chien, chat, baleine
groupe 2: brochet, hibou 3ème principe de subdivision: animaux terrrestres, marins et volants: groupe 1: chien, chat groupe 2: baleine, brochet
groupe 3: hibou La présence de définitions dans les corpus administratifs, législatifs, règlementaires, etc. montre bien la nécessité, pour une communauté donnée, de préciser les caractéristiques qui lui sont importantes pour la conduite de ses activités; elles peuvent différer de ce qu'entend un autre groupe dans un autre contexte. Qu'on prenne pur exemple la définition d'"étudiant" dans le Recueil des politiques de gestion (RPG) du Gouvernement du Québec, d'après le corpus de définitions extraites par Maurice Gingras: "étudiant, étudiante": un résident ou une résidente du Québec inscrit à temps complet à un programme régulier d'études secondaires, collégiales ou universitaires et qui a terminé sa scolarité de secondaire V ou qui est âgé de 16 ans ou plus le 30 juin de l'année de sa demande." (RPG 133-3/1/32). Pour qui connaÎt le contexte, les caractéristiques retenues dans la définition semblent pour le moins orientées vers l'embauche des étudiants pour un emploi d'été, emploi d'été que le même document définit ainsi: "emploi d'été": un emploi créé en vue d'embaucher un étudiant ou une étudiante au cours de la période d'été. (RPG 133-3/1/29). alors que le Petit Robert fournit cette définition pour étudiant:
"Personne qui fait des .études
supérieures et suit les cours d'une université,
d'une grande école."
On pourrait citer bien d'autres cas
qui montrent à quel point le contexte prime dans le choix
des caractéristiques.
Selon la sémantique cognitive,
le sens ne peut être étudié indépendamment
de toutes les capacités cognitives de l'homme. Il est lié
au vécu. Ce que la norme ISO prend pour des relations a
priori n'est autre que des relations acceptées par
les locuteurs de la langue commune. Ce ne sont pas des relations
"naturelles". C'est le résultat d'un consensus.
Mais le thésaurus est un vocabulaire de domaine de spécialité
destiné à faciliter la représentation et
l'interrogation des productions textuelles dans ce domaine. Il
devrait donc refléter les structures de référence
communes aux membres de ce champ d'activité et suivre les
changements de ces structures au fil du temps.
D'ailleurs des études sur les
relations établies a priori, selon la connaissance
intuitive que le(s) concepteur(s) du thésaurus avai(en)t
du domaine à un moment donné, ont révélé
des différences notables avec les relations extraites d'une
étude statistique des co-occurrences dans un corpus, à
un autre moment. Dans le Thésaurus Verrier ,
les relations entre corrosion , détergent
et verre creux n'avaient pas été inscrites,
car au moment de sa constitution, les lave-vaisselle n'avaient
pas encore fait leur entrée dans les foyers français
(Chastinet et Robredo, 1974).
CARACTERE PARTIEL ET ARBITRAIRE
DES REGROUPEMENTS
En somme, plusieurs types de regroupements
sont possibles et aucun ne suffit à représenter
de façon complète l'organisation conceptuelle du
domaine; il faut plutôt considérer les diverses possibilités
comme complémentaires. En privilégier un plutôt
qu'un autre revient à choisir de façon arbitraire
ce qui pourrait être utile. L'idéal pour un utilisateur
est de pouvoir accéder rapidement au regroupement le plus
parlant pour la tâche à accomplir. Heureusement la
technologie commence à supporter plusieurs types de représentations
concurrentes. En particulier l'hypertexte est suggéré
pour superposer des visions différentes, comme celle d'un
groupe d'utilisateurs par rapport à un autre (Agosti et
al. , 1989 ) ou bien d'un individu par rapport au groupe (Belkin
et al., 1991).
D'autre part, les études en
sémantique cognitive montrent qu'il vaut mieux penser en
termes de similarité, de ressemblance de famille, d'organisation
de concepts autour de prototypes, ou groupes de signification
quis se recouvent en partie (Geeraerts, 1991: 33) et évoluent
au fil du temps. Sinon les catégories sont forcées,
artificielles, comme l'ont fait remarquer Kukulska-Hulme et Knowles
(1989: 386).
CONCLUSION
Nous avons soulevé beaucoup
plus de questions que nous n'en avons résolues. Il est
clair que les normes et les manuels de thésaurus ne sont
pas à jour du tout et donc de peu de secours. Le temps
est venu de repenser la fonction, le contenu et le mode de représentation
des thésaurus. Plusieurs disciplines peuvent être
appelées à la rescousse pour assurer les fondements
sur lesquels développer de nouvelles méthodologies.
Actuellement, celles que nous pouvons développer souffrent
de l'absence d'une théorie globale et des limites des logiciels
disponibles.
L'évolution du repérage
dans les bases de données textuelles s'oriente vers deux
pôles contradictoires en apparence: plus d'interactivité
et plus de tâches déléguées à
la machine, ce qui commande à la fois plus de souplesse
dans la consultation et plus de rigueur dans la représentation.
Le contexte de production et d'utilisation
nous semble primordial pour développer des outils utiles
que ce soit à l'étape du choix des sources de collecte,
du choix des signifiants, des modes de regroupements, de la nature
des relations. Cela nous incite à regarder du côté
de la pragmatique et de la sémantique cognitive.
La confrontation avec les études
en terminologie et en intelligence artificielle est prometteuse.
Même si les finalités ne sont pas les mêmes.
Pavel (1989: 350) notait la similarité des techniques de
collecte et de systématisation des données en terminologie
et en IA. Il est clair que cela est vrai aussi pour la documentation.
"Le terminologue systématise
les moyens d'exprimer ces notions en fonction de la clientèle
des usages possibles, tandis que le cogniticien atomise les connaissances
du spécialiste et les formalise en équations logicielles.
La représentation formelle du savoir l'emporte ici sur
l'expression lingusitique des notions. C'est la différence
entre la dissémination du savoir-dire et la duplication
du savoir-faire."
Le documentaliste, quant à lui,
doit donner accès à tout ce qui a été
dit - et sera dit-, sous quelque forme que ce soit.
On peut donc prévoir que le
thésaurus tel qu'on l'a connu depuis trente ans va changer
considérablement.
BIBLIOGRAPHIE DES SOURCES CITÉES
Agosti, M.; Gradenigo, G.; Archi, A.;
Inghirami, B.; Nannuci, R.; Colotti, R.; Mattiello, P.; Di Giorgi,
R.M.; Ragona, M. New prospects in information retrieval techniques:
a hypertext prototype in environmental law. In: Online Information
89; Proceedings of the 13th International Online Information Meeting,
London, 12-14 December 1989: 483-494.
Ahlswede, Thomas. A tool kit for lexicon
building. In: Mann, William, ed. Proceedings of the Association
for Computational Linguistics (ACL) 23th Annual Meeting ;
1985 July 8-12; Chicago, Il. Morristown, NJ.: 268-276.
Ahlswede, Thomas; Evens, Martha. Generating
a relational lexicon from a machine-readable dictionary. International
Journal of Lexicography ; 1(3); 1988 Fall: 214-237.
Belkin, N.J.; Marchetti, P.G.; Albrecht,
M.; Fusco, L.; Skogvold, S.; Stokke, H,; Troina, G. User interfaces
for information systems. Journal of Information Science ;
17; 1991: 327-344.
Bertrand-Gastaldy, Suzanne. Les thésaurus
de recherche; des outils pour l'interrogation en vocabulaire libre.
Argus; 13(2); 1984: 51-58.
Brachman, Ronald J. What IS-A Is and
Isn't : An Analysis of Taxonomic Links in Semantic Networks. Computer
; 16(10); October 1983: 30-36.
Calzolari, Nicoletta. The dictionary
and the thesaurus can be combined. In: Evens, Martha, ed. Relational
Models of the Lexicon . Cambridge, England: Cambridge University
Press; 1988: 75-96.
Chastinet, Y. ; Robredo, J. Étude
des associations réelles entre descripteurs en vue d'améliorer
la qualité de l'indexage. Information et documentation
; 1974; 4: 3-30.
Cossette, Patrick. Les rapports
d'analyse environnementale et les langages de spécialité:
quelques approches . [Montréal]: École de bibliothéconomie
et des sciences de l'information. Université de Montréal;
avril 1991. 59 p. + annexes. (BLT 6271 - Recherche en analyse
documentaire)
David, Sophie; Plante, Pierre. De la
nécessité d'une approche morpho-syntaxique en analyse
de textes. ICO; Intelligence artificielle et sciences cognitives
au Québec; 2(3); septembre 1990: 140-151.
Eco, Umberto. Sémiotique
et philosophie du langage. Paris: PUF; 1988. 285 p. (Formes
sémioti-ques)
Frohmann, Bernhard P. An investigation
of the semantic bases of some theoretical principles of classification
proposed by Austin and the CRG. Cataloging and Classification
Quarterly ; Fall 1983; 4(1): 11-27.
Garcia Guitiérrez, Antonio Luis.
Estructure linguistica de la documentacion: teoria y método.
Murcia: Universidad: Secretariado de publicaciones; 1990.
Geeraerts, Dirk. Grammaire cognitive
et sémantique lexicale. Communications; 53; 1991:
17-50?. (numéro thématique sur la sémantique
cognitive)
Gémar, Jean-Claude. Terminologie,
langue et discours juridiques, sens et signification du langage
du droit. Meta; 36(1); mars1991: 275-283.
Grishman, Ralph; Kittredge, Richard,
eds. Analyzing Language in Restricted Domains: Sublanguage
Description and Processing. Hillsdale: LEA; 1986. 246 p.
Gross, Gaston. Degré de figement
des noms composés. Langages; 37(2); juin 1988: 57-72
Güntzer, U.; Jüttner, G.;
Seegmüller, G.; Sarre, F. Automatic thesaurus construction
by machine learning from retrieval sessions. In: User-Oriented
Content-Based Text and Image Handling; Proceedings of RIAO 88.;
Cambridge, MA; 1988 March 21-24; volume I: 587-596.
Heid, Ulrich; Freibott, Gerhard. Collocations
dans une base de données terminologique et lexicale. Meta;
36(1); mars1991: 77-91.
Hirschman, Lynette; Grishman, Ralph;
Sager, Naomi. Grammatically-based automatic word class formation.
Information Processing & Management ; 11; 1975: 39-57.
Houde, Serge. L'apport du Robert
électronique dans l'élaboration d'un thésaurus.
[Montréal]: Université de Montréal, École
de bibliothéconomie et des sciences de l'information; avril
1991. 59 p. + annexes.
Hutchins, W.J. Languages of Indexing
and Classification. Herts (England): Peter Peregrinus; 1975.
Ingwersen, P. Psychological aspects
of information retrieval. Social Science Information Studies
; 1984; 4: 83-95.
Kittredge, Richard; Lehrberger, J.
Sublanguage: Studies in Restricted Domains. Berlin: De
Gruyter; 1982.
Kukulska-Hulme, Agnes; Knowles, Frank.
L'organisation conceptuelle des dictionnaires automatiques pour
textes techniques. Meta ; 34(3); septembre 1989: 381-397.
Lancaster, F.W. Vocabulary control
in information retrieval systems. Advances in Librarianship;
7; 1977: 1-40.
Le Guern,Michel. Sur les relations
entre terminologie et lexique. Meta ; 34(3); septembre
1989: 340-343.
Lerat, Pierre. Sémantique
descriptive . Paris: Hachette; 1983. 128 p. (Langue, Linguistique,
Communication)
Lethuiller, Jacques. La synonymie en
langue de spécialité. Meta ; 34(3); septembre
1989: 443-449.
Ménard, Nathan. Mesure des relations
lexico-sémantqiues dans des textes scientifiques: problèmes
méthodologiques. Meta ; 34(3); septembre 1989: 468-478.
Meunier, Jean-Guy. Le traitement et
l'analyse automatique des textes. ICO; intelligence artificielle
et sciences cognitives au Québec; 2(3); septembre 1990:
9-18.
Moskovich, Wolf. Perspective paper:
quantitative linguistics. In: Walker, D.; Karlgren, K. Natural
Language in Information Science: Perspectives and Directions of
Research. Stockolm: Skriptor; 1977: 57-73.
Nakos, Dorothy. Étude comparée
des modes de formation des lexies complexes dans deux domaines
différents. Meta ; 34(3); septembre 1989: 344-351
Organisation internationale de normalisation.
Documentation - Principes directeurs pour l'établissement
et le développement de thésaurus monolingues.
ISO 2788 -1986 (F). 2ème éd. Genève: ISO.
32 p.
Paquin, Louis-Claude; Dupuy, Luc; Rochon,
Yves. Analyse de texte et acquisition des connaissances: aspects
méthodologiques. ICO; intelligence artificielle et sciences
cognitives au Québec; 2(3); septembre 1990: 95-113.
Pavel, Sylvia. Niveaux linguistiques
et terminologie de l'intelligence artificielle. Meta ;
34(3); septembre 1989: 344-351.
Pomian, Joanna. Statistiques et
connaissances de structure; application à la reformulation
des requêtes documentaires. Paris: Université
Pierre et Marie Curie - Paris VI; 1990. 281 p. Thèse de
doctorat.
Rada, R.; Barlow, J. Document ranking
using an enriched thesaurus. Journal of Documentation ;
47(3); 1991: 240-253.
Rastier, François. Sémantique
interprétative. Paris: PUF; 1987. 276 p. (Formes sémiotiques)
Rastier, François. Sens et
textualité. Paris: Hachette; 1989. 286 p. (Langue,
linguistique, communication)
Richer, Pierre. La création
automatique d'un thésaurus de recherche. Argus ;
15(1): 13-19.
Salton, Gerard. The SMART Retrieval
System . Englewood Cliffs, NJ: Prentice-Hall; 1971.
Sparck-Jones, Karen. Automatic Keyword
Classification for Information Retrieval. London: Archon Books;
1971.
Tardif, Hélène. Recherche
en analyse documentaire; [Constituion d'une liste de termes de
domaine à partir d'un corpus et de la banque de terminologie
Termium]. [Montréal]: Université de Montréal,
École de bibliothéconomie et des sciences de l'information;
avril 1991. 58 p. + annexes.
Wang, Yih-Chen; Vanderhope, James;
Evens, James. Relational thesauri in information retrieval. Journal
of the American Society for Information Science ; 36(1);
1985: 15-27.
Winston, Morton E.; Chaffin, Roger;
Hermann, Douglas. A taxonomy of part-whole relations. Cognitive
Science; 11(4); October-December 1987: 417-444.
ANNEXE: ILLUSTRATION D'UNE MÉTHODOLOGIE
DÉVELOPPÉE AVEC SATO POUR LA CONSTRUCTION DU THÉSAURUS
Cette annexe illustre brièvement
les principaux éléments de la méthodologie
développée à l'aide de SATO pour l'élaboration
et la gestion d'un vocabulaire de domaine. Elle ne comporte pas,
en général, les commandes utilisées pour
obtenir les résultats exposés.
Le lecteur qui désire approfondir
l'utilisation du logiciel pour effectuer le contrôle et
la structuration du vocabulaire pourra se référer
au document suivant:
Bertrand-Gastaldy, Suzanne. Avec la
collab. de Gracia Pagola. Le contrôle du vocabulaire
et l'indexation assistés par ordinateur; une approche méthodologique
pour l'utilisation de SATO. Montréal: Université
de Montrééal, École de bibliothéconomie
et des sciences de l'information; janvier 1992. Pagination variée,
env. 500 p. Les principales étapes à suivre figurent sur le schéma suivant.
Une fois la base de données
textuelle constituée et avant d'entreprendre les opérations
d'élaboration et de gestion d'un thésaurus, un ensemble
d'indices permet de juger de la stabilité du vocabulaire.
CHOIX DU MOMENT OPPORTUN
TAUX DE RENOUVELLEMENT DU VOCABULAIRE
Dans un corpus de textes portant sur
un même thème, plus la longueur augmente, plus le
taux d'accroissement du vocabulaire ralentit. A l'aide du logiciel
SATO, nous pouvons établir l'apport lexical introduit par
l'ajout d'un certain nombre de mots. Le plafonnement de la courbe
constitue un bon indicateur de la stabilité du vocabulaire.
TAUX DE RÉPÉTITIVITÉ
DU VOCABULAIRE
On constate aussi que le taux de répétitivité
(la moyenne) augmente à mesure que le corpus s'allonge,
car les mêmes mots ont tendance à être réutilisés
:
COMPORTEMENT DES FORMES DE FRÉQUENCE
1, 2 ET 3
Selon le modèle théorique
de Michéa, les formes de fréquence 1, 2 et 3 dans
un corpus stabilisé se comportent ainsi :
Valeurs attendues fréq. 1 = 1/2 du nombre total des formes dans le corpus fréq. 2 = 1/6 "
fréq. 3 = 1/12 "
Ce qui permet de dresser le tableau
suivant :
EXTRACTION DES FORMES SIMPLES
Dans un premier temps, la segmentation
du texte s'effectue sur les chaÎnes de caractères,
ce qui conduit à l'obtention du lexique des formes lexicales
simples du corpus.
Avec SATO, nous ne pouvons pas procéder
à la lemmatisation automatique de ces formes.
EXTRACTION DES FORMES COMPLEXES
CATÉGORISATION GRAMMATICALE
DU LEXIQUE
La projection des valeurs grammaticales,
par la consultation de dictionnaires, permet d'ajouter des informations
linguistiques aux formes du lexique afin de pouvoir extraire les
unités considérées comme les plus informatives
en documentation (noms, adjectifs, verbes) et afin de chercher
des suites formées de plusieurs mots susceptibles de correspondre
à des termes complexes.
...
RECHERCHE DE LOCUTIONS GRAMMATICALES
Afin d'éviter que les différents
éléments qui composent les locutions adverbiales,
prépositives et conjonctives ne viennent s'insérer
dans les expressions nominales à extraire plus tard, il
est nécessaire de procéder à leur blocage
avant toute recherche de séquences des expressions nominales.
Le logiciel SATO permet de lier des suites de formes à
l'aide d'un trait de soulignement et de les considérer
par la suite comme une entité unique.
PROCÉDURE MARQTERM
Recherche dans le corpus des suites
consécutives de catégories grammaticales selon de
configurations spécifiques. Ces modèles correspondent
à des expressions nominales susceptibles d'être des
termes du domaine.
CRITERES DE DÉCISION POUR
LE CHOIX DES TERMES REPRÉSENTATIFS DU DOMAINE
Afin de faciliter le choix définitif
de l'ensemble des termes simples et complexes qui appartiennent
au domaine, nous avons constitué une procédure qui
attribue un poids aux formes selon leur valeur grammaticale, leur
position danns le texte et leur fréquence. La pondération
plus forte reçue par certaines formes pourra constituer
un bon indice de leur appartenance ou non au domaine. Ainsi, nous
attribons +14 aux termes complexes , +10 aux noms communs, +2
aux verbes, +1 aux adjectifs. En outre, nous ajoutons +5 si les
formes se trouvent dans les titres et sous-titres ou la table
des matières (ce n'est pas cumulatif), dans la liste des
tableaux, le résumé, l'introduction et la conclusion.
Dans certains corpus, on voudra retenir systématiqueemnt
les termes qui font l'objet d'une définition, qui appartiennent
à un index, etc.
RÉSULTATS DE LA PROCÉDURE
DE PONDÉRATION
JUGEMENT DES EXPERTS
Pour établir l'indice de pertinence
et les limites conceptuelles du domaine, les experts mieux que
quiconque pourront établir le degré de pertinence
des descripteurs.
L'ajout aux formes du lexique d'autant
de propriétés lexicales qu'il y a d'experts permet
d'exprimer le choix de chacun:
Nous pourrions retenir comme descripteurs
à inclure dans le thésaurus les unités pour
lesquelles il y a eu consensus entre les experts ou du moins celles
pour lesquelles la majorité a exprimé son accord.
CONTROLE ET STRUCTURATION DU VOCABULAIRE
Ayant procédé au choix
des termes les plus représentatifs du domaine, l'étape
suivante consiste à contrôler et à structurer
le vocabulaire. Nous suggérons des regroupements par famille
et par facettes. Afin d'éviter des distorsions, nous procédons
à la recherche, dans le corpus, des formes susceptibles
d'introduire des définitions, des synonymes et variantes
orthographiques, des relations génériques, associatives.
RECHERCHE DE DÉFINITIONS
Concordance libre défini$ ...
définir
Le revêtement de surface est
désigné par les termes d'électrodéposition,
de galvanotechnique ou de galvanostégie. On peut le définir
comme l'action de déposer, par voie électrique,
un métal ou un alliage sur un autre métal ou des
plastiques.
définit
La complexation se définit
comme la formation d'un composé complexe par un agent complexant
ou chelatant.
REGROUPEMENT DES MOTS DE LA MEME
FAMILLE
RECHERCHE DE VARIANTES SYNTAXIQUES
D'EXPRESSIONS COMPORTANT DES MOTS DE LA MEME FAMILLE
Concordance libre récup$
méta$
récupéré
La solution peut être réutilisée
et le métal éliminé est récupéré.
récupérés
La quantité des métaux
récupérés est trop petite pour intéresser
les principales compagnies qui les utilisent.
récupèrent
Les procédés de séparation
physique, tels la précipitation, la filtration, la floculation
et l'évaporation, récupèrent les métaux
sous forme d'oxydes, d'hydroxydes ou de sels.
récupérer
L'objectif de ce rapport est de faire
une revue critique de la littérature sur les procédés
en usage et des nouvelles technologies qui permettent d'éliminer,
de récupérer et de recycler les métaux
lourds contenus dans les effluents industriels.
récupération
La récupération
de chacun des métaux n'est pas toujours possible.
RECHERCHE DE SYNONYMES ET DE VARIANTES
ORTHOGRAPHIQUES Concordance ordonnée est désign$ Concordance ordonnée sont désign$ Concordance libre et Concordance libre comme Concordance libre ou Concordance stricte ...
Le revêtement de surface est
désigné par les termes d'électrodéposition,
de galvanotechnique ou de galvanostégie.
le thénolyltrifluoroacétone
(TTA) possède une sélectivité
très élevée pour le cuivre, à ph très
bas;
Catégorisation des formes
équivalentes
L'ajout d'une propriété
lexicale équivalent permet de catégoriser
les formes équivalentes des descripteurs
REGROUPEMENT DE TERMES PAR FACETTES
Les suffixes peuvent servir à
détecter des formes dont les membres partagent une caractéristique
commune. Par exemple, les formes qui finissent par -ité
expriment souvent des qualités, celles en -ation
sont souvent des actions ou des processus.
La détection des formes dont
les membres partagent une caractéristique commune peut
aussi être réalisée par la recherche de concordances
de termes qui peuvent marquer cette caractéristique, par
exemple procédés ou processus:
procédés #2 *page=doc1/3/10 ... *page=doc1/3/15/6
*divis=résumé La première
regroupe les procédés courants pour éliminer
les métaux_lourds des effluents, tels: la précipitation_chimique_sous_forme_d'_hydroxydes,
de carbonates, de sulfures, de phosphates ou de métal_élémentaire;
la coprécipitation; la séparation_solide-liquide_par_filtration,
flottation, sédimentation ou centrifugation; la coagulation-floculation,
et le traitement_biologique.
processus $10 *page=doc1/8/17/6 ... *page=doc1/8/21/2
*divis=intro Ces processus sont
: la précipitation_chimique, la coagulation-floculation,
l'échange-ionique, l'extraction_par_solvant, la cémentation,
la complexation, les traitements_électrochimiques ou biologiques,
l'évaporation et la séparation_par_membranes.
Catégorisation par facettes
L'ajout d'une propriété
lexicale facette permet de catégoriser le lexique des descripteurs:
RECHERCHE DE RELATIONS HIÉRARCHIQUES
DANS LE CORPUS Concordance stricte est un Concordance stricte est une Concordance stricte sont : Concordance ordonnée $*gramr=nomcommun \($*gramr=nomcommun \) Concordance stricte tels l' Concordance stricte tels la Concordance stricte tels que ...
Le procédé est d'autant
plus intéressant qu'il y a présence de métaux_précieux
(or, argent,platine) dans les effluents.
L'utilisation de Fes comme co-précipiteur
des métaux_lourds (cuivre, cadmium, nickel, chrome
et zinc) s'avère avantageuse comparativement aux
hydroxides
Catégorisation des formes
hiérarchiques
On ajoute une propriété
hiérarchique:
RECHERCHE DE TERMES ASSOCIÉS
Avec la commande Tamiser, on
filtre, pour une concordance donnée, les formes qui sont
utilisées dans le même contexte, la phrase par exemple:
Catégorisation des termes
associés
L'ajout d'une propriété
Associés est possible, mais le nombre de valeurs risque
d'être encombrant:
MISE À JOUR: EXTRACTION DES
MOTS NOUVEAUX
La mise à jour du vocabulaire
est facilitée dans SATO car, au fur et à mesure
que des textes sont inclus dans le corpus, le logiciel permet
de connaÎtre les nouvelles formes introduites par ces textes
et d'appliquer systématiquement les traitements seulement
à ces formes:
|