 |
 |
|
|
|
INTRODUCTION
Pour faire face à l'afflux
prochain de jugements sur support informatique généré
par la saisie à la source, une équipe de recherche
constituée de chercheurs du Centre d'analyse de textes
par ordinateur(ATO) de l'Université du Québec à
Montréal et de l'École de bibliothéconomie
et des sciences de l'information de l'Université de Montréal
a présenté un projet de conception de système
expert pour assister l'analyse des jugements. Cette recherche,
en cours de réalisation, bénéficie d'une
subvention du CEFRIO (Centre francophone de recherche en informatisation
des organisations) à laquelle contribuent à la fois
SOQUIJ (Société québécoise d'information
juridique) et le ministère des Communications du Québec
dans le cadre du projet Delta.
Dans le texte qui suit, nous présenterons
brièvement nos hypothèses de travail et les contraintes
à respecter pour la réalisation du projet. Puis
nous énumérerons les sources de données auxquelles
nous recourons . Nous nous attarderons à l'explicitation
des approches méthodologiques pour en faire ressortir la
complémentarité et nous exposerons, pour terminer,
la façon dont sera élaboré le système
expert.
LE PROJET
Le projet s'appuie sur la triple
hypothèse qu'il est possible: 1) de modéliser les
décisions prises par les conseillers juridiques pour analyser
les arrêts; 2) de construire des algorithmes d'analyse
des jugements en plein texte pour assister ces décisions;
3) d'opérationnaliser les algorithmes dans un milieu réel
pour un corpus fortement normalisé comme celui de la jurisprudence.
Les chercheurs devront remplir
le mandat confié en respectant à la fois la plateforme
technologique et les outils documentaires de SOQUIJ. Les logiciels
qui supportent la recherche tournent sur micro-ordinateurs IBMPC
ou compatibles, matériel également utilisé
par SOQUIJ . Quant aux algorithmes de calcul statistique, ils
sont mis au point sur les ordinateurs centraux des universités,
puis transférés sur micro pour la réalisation
du prototype. Au terme du projet, il appartiendra à l'organisation
de décider du type de matériel devant supporter
la mise en production. Comme le système expert devra assister
le travail humain sans le remplacer, il n'est pas prévu
d'abandonner les outils documentaires actuels. Néanmoins
ceux-ci pourront être enrichis et modifiés pour s'adapter
aux opérations automatisées.
LES SOURCES DE DONNÉES
La modélisation, la mise
au point et l'opérationnalisation des algorithmes s'appuient
sur plusieurs sources de données, dont certaines se trouvent
déjà sur support informatique. Il s'agit des notices
bibliographiques produites à la suite des différentes
opérations d'analyse, des textes intégraux des jugements
et des critères explicites ou implicites auxquels recourent
les conseillers juridiques pour prendre leurs décisions.
Les résultats des différentes
opérations d'analyse effectuées par les conseillers
juridiques constituent un dépôt précieux de
l'expertise humaine qu'il faut extraire afin de pouvoir en reconstituer
sinon les procédures, du moins l'aboutissement. Il s'agit:
a) des rubriques de classification; b) des mots-clés contrôlés
issus du thésaurus et des mots-clés libres assignés
dans la manchette à la suite de l'indexation; c) du résumé
structuré et des autres éléments d'une notice
(nom des parties, tribunal, citations de lois ou de jurisprudence,
etc.). Notre échantillon est constitué de 1068 notices
de Jurisprudence Express publiées entre janvier
et juin 1991.
Certains des jugements sont,
en raison de leur importance, publiés sous forme intégrale,
par exemple dans Recueil de Jurisprudence du Québec
et disponibles sur disquettes. D'autres, ceux qui sont éliminés
à la source ou conservés dans des classeurs pendant
un an sont reçus pour le moment sur support papier et il
nous faut les saisir et procéder à la reconnaissance
optique des caractères pour les exploiter. En effet, la
comparaison des différentes caractéristiques de
chaque groupe de jugements permettra de trouver les éléments
formels ayant pu justifier la discrimination.
Les jugements comportent des régularités
exploitables par des analyseurs automatiques: "La jurisprudence
est un exemple frappant de textes dont la structure est normalisée."
(Didier, 1990: 167), ce qui rend possible, croyons-nous, le recours
aux méthodes développées à l'intérieur
de la théorie des langages de spécialité
(Grishman et Kittredge, 1986; Kittredge et Lehrberger, 1982).
La forme est régie par les contraintes coutumières,
d'après Didier (p. 168) qui affirme: "Le rapport judiciaire
est construit sur un plan immuable composé de deux éléments:
le jugement lui-même et les informations complémentaires
qui l'encadrent en tête et en queue." et qui ajoute
(p.170): "On constate que la structure interne des jugements
devient de plus en plus rigoureuse, que les juges n'hésitent
plus à intégrer des tables des matières dans
leurs motifs, surtout lorsque ceux-ci sont longs et complexes."
Quant au fond, plus difficile à cerner, Poirier (1985)
l'a étudié pour établir des normes de rédaction
des résumés respectant la structure d'information
des textes intégraux.
Les conseillers juridiques
mettent en oeuvre un savoir très spécialisé
qui tient à la fois de la connaissance intime des différents
domaines de droit dans lesquels chacun a développé
une expertise, de la nature des textes analysés, des politiques
régissant chacune des publications et banques de données
produites ainsi que des besoins des différents types d'utilisateurs
auxquels elles sont destinées. Ce savoir est actuellement
très peu codifié. À part la sélection
définie, dans ses grandes lignes seulement, par l'annexe
2 au Règlement sur la cueillette et la sélection
des décisions judiciaires (Loi sur la Société
québécoise d'information juridique - L.R.Q.,
chap. S-20, art. 21) et aux recommandations de Poirier (1985)
pour la rédaction des résumés, l'équipe
de recherche doit recourir aux techniques d'enquête cognitive
(entrevues et observations en situation de travail) pour mettre
à jour les pratiques développées par les
experts humains dans la prise de connaissance et l'analyse des
jugements.
LES APPROCHES MÉTHODOLOGIQUES :
COMPLÉMENTARITÉ DES TRAITEMENTS STATISTICO-LINGUISTIQUES
ET DE L'ENQUÊTE COGNITIVE
Les données issues de l'analyse
humaine, soumises à une combinaison de traitements que
nous allons exposer, puis mises en correspondance avec les données
des textes intégraux, révèlent des tendances
et des anomalies qui servent à questionner les outils,
les pratiques et à orienter ou à corroborer l'étude
des savoir-faire. La multiplicité des données et
des types de traitement dépasse en envergure et en complexité
les études antérieures de ce genre (Todeschini et
Farrell, 1989).
Enrichissement des textes et des notices
par ajout de propriétés
Les traitements consistent à
mettre au jour une série de caractéristiques propres
aux unités lexicales ou textuelles, l'objectif étant
de découvrir lesquelles de ces unités et lesquelles
de leurs propriétés permettent de reproduire les
résultats des analyses effectuées antérieurement
par les conseillers juridiques. Nous utilisons pour cela le langage
ICON (Griswold, 1990) et le logiciel SATO (système d'analyse
de textes par ordinateur) conçu au centre ATO (Daoust,
1992). La mise au point des algorithmes s'effectue à partir
des notices de Jurisprudence Express qui offrent le triple
avantage d'être fortement codifiées, relativement
courtes (environ une page) et de refléter l'expertise des
analystes. Ils sont ensuite adaptés et appliqués
aux textes intégraux.
Les propriétés attribuées
aux données textuelles, en contexte ou hors contexte, consistent
en l'ajout de connaissances de nature diverse qui enrichissent
les chaÎnes de caractères immédiatement accessibles
à l'ordinateur et accroissent le nombre d'opérations
auxquelles on peut ensuite les soumettre. Il peut s'agir d'informations
résultant de décomptes statistiques, de connaissances
générales de la langue (nature grammaticale des
lexèmes), de connaissances spécifiques au domaine
(vocabulaire, structure des jugements), de connaissances "documentaires"
(champs d'une notice, appartenance des lexèmes aux langages
documentaires, signification des différentes conventions
typographiques dans les enregistrements), etc. Elles sont interprétables
par un être humain et résultent de traitements automatiques,
assistés ou humains. En voici quelques exemples:
- Fréquence dans le corpus,
avec valeurs calculées automatiquement par SATO:
- Propriétés grammaticales
des formes simples hors contexte (nom, verbe, adjectif, etc.)
résultant de la projection sur le lexique du corpus de
bases de données lexicales:
- Propriétés typographiques
(lettres capitales reconnues par SATO, spécifications de
polices de caractères dans le logiciel de traitement de
texte, converties avec le langage ICON en valeurs de propriétés:
gras, italiques et soulignés): Format reçu de la SOQUIJ:
^N Les dispositions
du ^ICode de procédure civile^N relatives
à l'amendement doivent recevoir une interprétation
aussi large que possible. Format SATO après conversion:
Les dispositions du *typo=italique Code
de procédure civile *typo=nil relatives à
l'amendement doivent recevoir une interprétation aussi
large que possible.
- Position dans la macro-structure;
des algorithmes ont été développés
et implantés en ICON pour attribuer des valeurs de propriété
admissibles par SATO, selon les différentes subdivisions
propres aux notices: . Numéro d'identification . Tribunal ayant rendu le jugement . Manchette . Litige . Contexte . Décision
. Références (nom des parties,
nom des juges, citations de lois, d'articles de lois)
Nous tenterons d'automatiser également
la reconnaissance des passages concernant le litige, le contexte
et la décision dans le texte intégral des jugements,
à partir de certaines régularités stylistiques
ou lexicales.
- Position dans le texte, selon
les subdivisions textuelles courantes en phrases et en paragraphes;
un algorithme implanté en ICON numérote les phrases
et identifie la dernière (de) et l'avant-dernière
(ad ) de chaque partie du résumé:
NOTICE 91-3.STR
*par=ident*typo=nil<ND>91-3
*par=provenance<HD>COUR D'APPEL
*par=manchette
ASSURANCE -- assurance de responsabilité -- recours contre
le tiers responsable -- option -- article 2603 C.C. -- interdiction
de cumul -- amendement.
*par=litige *phr=1 *ord=ad
Appel d'un jugement de la \Cour supérieure ayant
accueilli une requête en irrecevabilité. *phr=2
*ord=de Rejeté, avec dissidence.
*par=contexte *phr=1Le
18 février 1988, l'appelante a intenté une action
contre la mise en cause \Fontaine, lui réclamant
23 688$ à titre de dommages à la suite d'un incendie
provoqué par sa négligence. *phr=2Quelques
mois plus tard, l'appelante a fait signifier une déclaration
amendée qui ajoutait la compagnie d'assurances intimée
à titre de défenderesse et qui concluait à
la condamnation conjointe et solidaire des codéfenderesses.
L'intimée a alors présenté une requête
en irrecevabilité fondée sur le fait que l'appelante
n'avait aucun recours contre elle puisque, en poursuivant \Fontaine,
elle avait exercé l'option prévue à l'article
2603 \C..\C.. . *phr=3La requête
en irrecevabilité a été accueillie malgré
la demande verbale d'amendement présentée par l'appelante
visant à modifier la désignation des parties et
à ne maintenir que l'intimée à titre de défenderesse,
reléguant \Fontaine au rang de mise en cause. [...]
*par=décision *phr=1*typo=italique
\Mme la juge \Tourigny
et \M.. le juge \Proulx: *typo=nil Les
dispositions du *typo=italique Code de procédure
civile *typo=nil relatives à l'amendement doivent
recevoir une interprétation aussi large que possible. *phr=2
Cependant, une interprétation, aussi large soit--elle,
ne peut écarter une disposition de droit substantif incluse
dans le *typo=italique \Code civil. *typo=nil *phr=3
Le législateur a voulu que, en intentant un recours,
la partie demanderesse fasse un choix, ainsi que l'a confirmé
\M.. le juge Mayrand dans l'arrêt \L'\Union
québécoise, mutuelle d'assurance contre l'incendie
c.. \Mutuelle des \Bois-Francs: [...]
*par=référence
Compagnie d'assurances Traders générale c. Laurentienne
générale, Compagnie d'assurances inc.. Juges
Tourigny, Proulx et Chouinard (diss..). C.A.
On remarque que, à l'issue
du même traitement, les sigles et abréviations ont
été dépistés et marqués, ainsi
que les majuscules de noms propres et les tirets de pronoms personnels
inversés.
- Appartenance au langage de spécialité,
au domaine; des procédures ont été mises
au point pour extraire, à partir de patrons catégoriels
(nom + adjectif; nom + de + nom, etc.), des unités lexicales
complexes susceptibles de correspondre à des termes du
domaine tout comme certains unitermes (le détail des opérations
se trouve dans Bertrand-Gastaldy, 1992):
- Appartenance au plan de classification
et au thésaurus élaborés par l'organisation:
les outils documentaires, disponibles sur support informatique,
sont convertis en format SATO et projetés sur les manchettes,
ce qui permet de catégoriser à la fois les rubriques,
les mots-clés contrôlés (certains peuvent
provenir des deux outils à la fois et ce sont des caractéristiques
comme la position ou la typographie qui serviront à la
désambiguïsation ultérieurement) et, par défaut,
les mots-clés libres:
*par=manchette
ASSURANCE*pc=oui -- assurance de responsabilité*mot-clé=oui
-- recours contre le tiers responsable*mot-clé=oui
-- option*th=oui -- article 2603 C.C. -- interdiction de
cumul*mot-clé=oui -- amendement*th=oui.
- Propriétés lexico-sémantiques:
pour que le système puisse suggérer des mots-clés
contrôlés aux conseillers juridiques, il doit détecter
dans les textes les différentes formulations d'un concept
regroupées dans le lexique grâce à une propriété
Synonymes. Certains de ces synonymes- ou termes jugés équivalents
d'un point de vue documentaire- sont déjà répertoriés
dans le thésaurus sous forme de non-descripteurs et l'on
peut traduire ainsi les relations dans SATO:
- Appartenance à tout autre catégorie jugée pertinente pour les fins de l'analyse:
Certaines informations sont importantes pour
caractériser le domaine du droit auquel un jugement est
susceptible d'appartenir. Les noms propres (décelés
d'après l'environnement du mot qui commence par une lettre
capitale et qui n'est pas placé en début de paragraphe
ni précédé d'un point) peuvent être
subdivisés en noms de personnes, noms géographiques,
noms de municipalités, noms d'organisations, elles-mêmes
fractionnées en différents sous-groupes (compagnies
d'assurances, organismes administratifs, syndicats, etc.):
Lorsqu'on cherche, grâce
à la commande Distance dans SATO, quel est le vocabulaire
qui distingue le plus la subdivision Litige des autres subdivisions
du résumé, on obtient une liste de ce genre, dans
un ordre décroissant d'importance: octobre, janvier,
novembre, décembre, mai, juillet, suite, septembre, motif,
août, compagnie, avril, mois, demanderesse, février,
ans, mars, employeur, jours, défenderesse, défendeurs,
année, syndicat. Ce sont donc surtout les marqueurs
de temps qui jouent un rôle discriminant et, pour catégoriser
automatiquement les passages des jugements en texte intégral
qui traitent du contexte, on devra produire un algorithme qui
ira chercher une forte concentration de formes ayant cette propriété.
Il faut donc catégoriser le vocabulaire en ce sens.
- Marqueurs textuels divers: il
peut être nécessaire de détecter les passages
où le juge argumente sa décision, ceux qui réfèrent
à une loi, ceux qui introduisent une nouvelle interprétation
jurisprudentielle, ou tout autre fragment textuel propre à
assister les opérations de tri, de classification ou d'indexation.
Grâce aux différents
traitements exposés, il est possible de catégoriser
des unités lexicales ou textuelles et de procéder
à des extractions de variables multiples selon les caractéristiques
retenues: formes simples, formes simples affectées, hors
contexte, de la (ou des) valeurs de propriété grammaticale,
lexies complexes, termes du domaine, rubriques de classification,mots-clés
contrôlés (descripteurs), mots-clés libres,
titres de lois, nom des parties en présence, déclencheurs
argumentatifs divers (de citations, de décisions, d'interprétation
jurisprudentielle, etc.). On peut les choisir selon leur fréquence,
selon leur position dans le texte, selon le domaine de droit,
le tribunal, le juge, etc. Par exemple, on peut vouloir vérifier
si les références aux lois sont de bons indices
pour la classification des textes dans un domaine du droit.
Traitements statistiques
Afin d'évaluer la performance
des divers types de données et de leurs différentes
propriétés pour prédire les décisions
prises par les conseillers juridiques, nous les soumettons à
une analyse de discrimination, avec le logiciel SPSS. Auparavant,
nous procédons à un filtrage destiné à
réduire le nombre de variables. Pour trouver les meilleurs
candidats, nous avons testé, jusqu'à présent,
la valeur discriminante de Salton et le chi 2 et nous avons confronté
les résultats avec ceux que procure un choix aléatoire.
Ainsi, pour chaque texte, nous procédons à un traitement
SATO qui produit un ensemble d'indices numériques. Ces
indices sont ensuite fusionnés dans un fichier unique à
raison d'une fiche par texte qui, pour la vérification
de la classification, par exemple, contient en outre la rubrique
de classification attribuée par les conseillers juridiques.
L'algorithme permet d'éliminer les indices possédant
un faible pouvoir discriminant. Il permet aussi d'évaluer
la performance d'ensemble des indices conservés en comparant
la classification générée par les indices
à celle qui correspond au jugement des conseillers.
Voici quelques exemples de résultats
obtenus à partir d'indices extraits des résumés:
Les excellents résultats
obtenus dans l'exemple ci-dessus s'expliquent sans doute par le
fait que les résumés sont rédigés,
à l'intérieur d'un domaine, par le même indexeur.
On peut s'attendre à une moins bonne performance lorsque
les jugements des différents juges, dans les différentes
cours, seront traités.
Nous avons voulu vérifier
également dans quelle mesure les regroupements de descripteurs
effectués de façon très lâche dans
le thésaurus (puisqu'il n'y a pas de relations hiérarchiques
ni de regroupements par thèmes ou par facettes) d'une part,
pourraient bénéficier d'une structuration par domaine
de droit et, d'autre part, correspondaient aux regroupements réalisés
lors de l'indexation. Pour cela, nous avons procédé
à des analyses de co-occurrences et à des analyses
de "clusters".
Descripteurs du thésaurus
co-occurrant plus d'une fois avec la rubrique de classification
Famille (avec indication de la fréquence de co-occurrence):
Descripteurs co-occurrant avec
le descripteur Pension alimentaire:
Descripteurs du thésaurus
regroupés dans la classe 37 (que l'on pourrait étiqueter
Famille à cause des ressemblances de contenu avec la liste
présentée plus haut sous cette rubrique), selon
l'analyse de "clusters" effectuée avec SPSS ("single
linkage method"):
Les résultats montrent,
dans plusieurs cas, une bonne convergence entre les différents
regroupements statistiques et ceux que l'on peut reconstituer,
parfois péniblement, dans le thésaurus en suivant
le réseau de renvois voir aussi. On peut penser
qu'alors un regroupement statistique favoriserait la consultation
du thésaurus en offrant, d'un seul coup d'oeil, l'ensemble
des descripteurs reliés que l'on peut colliger seulement
en s'astreignant à tourner de nombreuses pages pour obtenir
une vue plus synthétique comme nous avons représentée
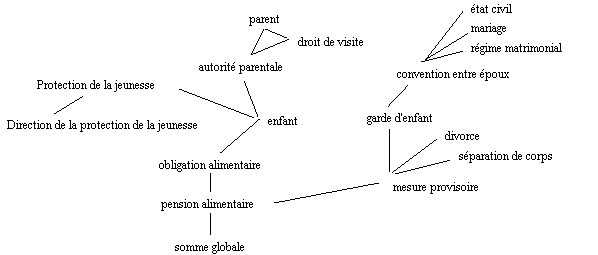
graphiquement dans le schéma ci-dessous. On y retrouvera
la plupart des descripteurs qui figurent dans le "cluster"
présenté plus haut, à l'exception des descripteurs
partage, prestation compensatoire, patrimoine familial, rétroactivité,
provision pour frais qui, dans le thésaurus ne sont
reliés à aucun autre descripteur:
Le tableau 1 résume l'ensemble
des traitements que nous venons d'exposer.
Enquête cognitive
Les entrevues et les observations
avec les personnes chargées d'analyser les jugements permettent
à la fois de compléter les analyses de données
exposées précédemment et de les orienter.
Nous cherchons les techniques employées pour parcourir
un texte, les différentes parties du texte examinées
pour prendre une décision de tri, de classification, de
résumé, d'indexation, les connaissances utilisées
(importance de telle ou telle cour, poids à accorder à
la nature des parties en cause, marqueurs du raisonnement du juge,
contenu actuel de la base de données, besoins des utilisateurs,
etc.), les catégorisations effectuées , les inférences
faites pour passer des expressions en langue naturelle à
leurs équivalences dans le thésaurus. Nous procédons
donc selon une boucle: textes _> conseillers juridiques _>
textes. Il est à noter que l'étude cognitive des
opérations d'analyse documentaire ne bénéficie
pas d'une longue tradition (David, 1991; Engres-Niggemeyer, 1990;
Farrow, 1991)
Nous allons illustrer comment nous
procédons pour modéliser les algorithmes de classification.
Selon les responsables de l'analyse,
l'appartenance d'un jugement à un domaine du droit peut
être décelée, dans quelques cas (DROIT PÉNAL,
FAMILLE, TRAVAIL), d'après certains renseignements contenus
dans la première page: le tribunal, le nom des parties
ou la procédure entreprise, entre autres. Un jugement provenant
de la Chambre d'expropriation de la Cour du Québec traitera
assurément du domaine de l'expropriation. Par ailleurs,
un jugement dont l'une des parties est un syndicat pourrait vraisemblablement
aborder le droit du travail. Enfin, un jugement qui mentionne
qu'il s'agit d'une requête en irrecevabilité à
l'encontre d'une action en dommages-intérêts pourrait
être classé en procédure civile. Mais comme
il existe des chevauchements entre plusieurs rubriques de classification
(le DROIT CIVIL recoupe OBLIGATIONS, VENTE, CONTRATS, entre autres)
et comme plusieurs rubriques peuvent être attribuées
à un même jugement, il est parfois nécessaire
de consulter le texte du jugement, pour prendre connaissance soit
du vocabulaire employé par le juge, soit des lois ou articles
du code civil cités.
Tableau 1: TRAITEMENT DES NOTICES DE JURISPRUDENCE
EXPRESS, DU THÉSAURUS ET DU PLAN DE CLASSIFICATION Pré-traitement de la base de données Pré-traitement du thésaurus de Jurisprudence Express et du plan de classification Segmentation en notices | Segmentation en groupes de 100 notices | Segmentation de chaque notice en paragraphes | Prétraitement de certains caractères: | Identification des majuscules de noms propres | Désambiguïsation du point d'abréviation | Catégorisation des paragraphes du résumé | Numérotation des phrases à l'intérieur des paragraphes | Catégorisation des avant-dernières et dernières phrases | | | | | | | V |-> Traitement des unités textuelles et lexicales | Catégorisation et extraction: | . des manchettes et de leurs unités lexicales | . rubriques de classification | . mots-clés contrôlés (descripteurs) | . mots-clés libres | . des autres parties des résumés et des différentes parties des textes ainsi que de | leurs unités lexicales: BDL | . formes simples | | . formes simples affectées des valeurs de catégories grammaticales <| | . expressions nominales complexes | . termes du domaine | . catégories sémantiques (noms propres, indicateurs de temps, etc) | . déclencheurs argumentatifs divers | . etc. | |-> Filtrage des données | . sur les propriétés attribuées | . sur leur comportement: fréquences, valeur discriminante, chi2, etc. | |-> Analyse de discrimination | . recherche des meilleurs prédicteurs pour le tri, la classification et l'indexation | . vérification de la constance de classification | |-> Analyse de co-occurrences et analyse de clusters . Étude des regroupements entre unités lexicales de la manchette, unités lexicales du résumé et des textes pour: . enrichissement et modification éventuelle des outils documentaires (thésaurus,plan de classification)
Prenons l'exemple du domaine ASSURANCE.
Sur la première page, le tribunal qui rend la décision
n'est pas un bon indice, dans ce cas. Si le nom d'une des parties
désigne une compagnie d'assurances, il est possible mais
pas certain qu'il faille classer le jugement dans ASSURANCE; une
compagnie d'assurances qui a indemnisé son assuré
peut, en effet, poursuivre la personne qui lui a causé
des dommages et il faudrait alors classer le jugement dans RESPONSABILITÉ.
Le fait que, dans le texte du jugement, les articles 2468 à
2676 du Code civil ou bien la loi sur les Assurances soient cités,
vient renforcer le second indice. Si, de surcroÎt, le jugement
comporte les termes comme: assurance-automobile, assurance
collective, assurance de choses ou ses spécifiques: assurance-incendie,
assurance-vol, assurances de personnes ou ses spécifiques:
assurance-vie, assurance-invalidité, assurance-accident,
ou encore assurance (de) responsabilité, assurance
maritime , alors on peut prendre la décision avec une
quasi-certitude de ne pas se tromper.
Une fois en possession de ces renseignements,
nous tentons de corroborer les affirmations des experts par l'analyse
des corpus. Ainsi, dans notre échantillon, nous constatons
que les jugements classés dans le domaine ASSURANCE se
distribuent comme suit:
Une compagnie d'assurance ou d'assurance-vie
constitue une partie dans 21 des 26 jugements classés dans
ce domaine.
Les articles du Code civil cités
se situent bien dans la fourchette indiquée plus haut:
2481, 2482, 2505, 2516, 2532, 2546, 2547, 2563, 2564, 2576, 2579,
2586, 2603.
Trois lois sur les assurances sont
citées: loi sur les assurances, loi sur l'assurance-automobile,
loi sur les assurances du Québec. Voici le vocabulaire le plus utilisé (sous forme d'unitermes, dans les résumés seulement):
Les résultats obtenus sont
ensuite soumis aux conseillers juridiques pour commentaires et
compléments d'information, si nécessaire. Il est
alors possible de formuler en règles d'inférences
l'analyse dont les critères textuels ont été
explicités.
Pour l'indexation, nous procéderons
de la même façon, mais notre analyse sera plus fine,
en raison de la nature même de l'opération. Cela
implique, entre autres, que nous identifions si les conseillers
juridiques extraient les concepts retenus d'une subdivision du
résumé plutôt que d'une autre: le litige,
le contexte ou la décision, si des algorithmes d'extraction
automatique basés sur des indices comme le chi2 ou la valeur
discriminante reproduisent avec suffisamment de fidélité
leurs décisions, quelles sont les propriétés
des termes retenus, dans quelle mesure les termes choisis correspondent
aux formulations du juge ou résultent d'une normalisation
de vocabulaire. Parmi les propriétés possibles des
termes retenus, étant donné ce que nous savons des
processus d'indexation humaine en général, nous
testerons la performance des critères suivants: la nature
grammaticale, la fréquence, la position dans le texte (début
ou fin de paragraphe), la position dans la superstructure des
jugements, la typographie.
LE SYSTÈME EXPERT
Pour l'implantation du système
d'aide à l'analyse, nous avons retenu la technologie des
systèmes experts, malgré les limitations de ce formalisme
(découpage arbitraire de l'espace du problème, entre
autres). La formulation des modèles en énoncés
conditionnels et les règles d'inférences, présentent
des avantages ergonomiques. En effet, le recours à un générateur
de système expert (GSE) permet à des non-informaticiens,
après un entraÎnement approprié, de formuler
de façon autonome les règles pour un système
qui peut être très complexe. En voici un exemple
dans la veine de ce que nous avons expliqué plus haut:
Si article(s)_de_loi_cité(s) = "24?? à 26?? du Code Civil" ET nom_des_parties = "compagnie d'assurance" ET mot(s)_du_texte = ("police d'assurance" OU "contrat d'assurance")
ALORS domaine
= ASSURANCE.
De plus, puisque les règles
d'inférences sont des énoncés autonomes dont
l'enchaÎnement est assuré par un mécanisme
informatique lui aussi autonome appelé moteur d'inférences,
il n'est pas nécessaire de prévoir à l'avance
le déroulement complet de la résolution du problème.
Cela favorise une méthodologie de développement
par prototypage où l'on commence à implanter une
solution avant qu'elle ne soit complètement planifiée.
Le système joue un rôle heuristique en ce que la
validation des règles d'inférences sur des cas concrets
permet de transformer la solution envisagée. Le formalisme
d'expression des règles, leur lisibilité, y compris
par ceux qui n'ont pas participé à leur élaboration,
et la modularité qu'elles permettent dans la construction
des modèles, facilitent l'évolutivité autant
latérale qu'en profondeur du système. L'évolution
sera latérale si de nouvelles règles sont ultérieurement
formulées pour prendre en compte d'autres cas dans le
processus de solution; elle sera en profondeur si le processus
de solution est complété par des étapes subséquentes
ou encore inclus dans un processus plus global.
La plupart des systèmes
experts permettent la qualification de la relation qui est faite
par le développeur entre des hypothèses et une conclusion.
Cette qualification, qui prend la forme d'un coefficient, est
prise en compte par un modèle de cumulÎ qui
a pour fonction d'une part d'atténuer la valeur des validations
subséquentes lorsqu'une validation est affectée
d'un coefficient incertain et, d'autre part de renforcer la valeur
d'une validation si elle a déjà été
faite. Ces mesures quoique imparfaites permettent d'exprimer la
confiance que l'on devrait avoir face aux résultats d'une
consultation. Grâce à la prise en compte de l'incertitude,
le système peut aboutir à plusieurs réponses,
chacune étant qualifiée d'un coefficient cumulé
indiquant la confiance qu'on peut avoir. Cette façon de
faire présente l'avantage de faire ressortir toutes les
possibilités étant donné la configuration
d'indices dépistés. Il a été prouvé
qu'il est plus facile cognitivement de rejeter une solution inappropriée
que de trouver la bonne solution sans suggestions. Ce dispositif
s'avèrera sans doute très utile, dans les cas où
plusieurs rubriques de classification seront proposées.
Ainsi, dans l'exemple fourni précédemment, une autre
règle pourrait, à partir de la conjonction des mêmes
indices plus un autre mot-clé affirmer qu'il pourrait aussi
s'agir de domaine de la responsabilité. À la suite
de la consultation, l'utilisateur serait en face de deux domaines
potentiels, assurance et responsabilité.
Comme les systèmes experts
offrent la possibilité de documenter le cheminement suivi
lors de la résolution de problème, l'utilisateur
peut valider la ou les réponses obtenues et, le cas échéant,
apprendre à partir des explications fournies.
Pour implanter les modèles
que nous aurons construits, nous allons utiliser le GSE fourni
dans l'Atelier Cognitif et TExtuel - ACTE (Paquin, 1992a). L'Atelier
offre une représentation matricielle des connaissances
appelée objets valués. Ce formalisme permet une
interface directe avec les sorties de SATO. Chacun des mots d'une
séquence donnée ainsi que l'ensemble des annotations
statistico-linguistiques sont transformés en autant de
faits qui valideront les hypothèses des règles d'inférences
appropriées qui à leur tour amèneront à
une solution documentée, soit la sélection ou le
rejet d'une décision, soit l'attribution d'une ou plusieurs
rubriques du plan de classification (Paquin, 1992a).
CONCLUSION
La complémentarité
des approches utilisées pour la modélisation constitue
une des originalités de notre projet. Bien que recommandée
à plusieurs reprises (Chaumier et Dejean, 1992; Doszkocs,
1986; Meunier et al., 1987), en raison de la multiplicité
des connaissances mises en oeuvre pour l'analyse du matériau
textuel orientée vers des fins documentaires, elle n'a
pas encore été appliquée fréquemment,
en tout cas pas avec cette ampleur. Ceci permet, nous semble-t-il,
un heureux compromis qui tient compte de caractéristiques
exigeant parfois des solutions contradictoires, dans l'état
de développement actuel des technologies: matériau
textuel très complexe à analyser, mais nécessitant
néanmoins des approches de nature linguistique et cognitive,
volume important des données prohibant des analyses très
fines et pouvant bénéficier des effets de nombre,
savoir-faire de plusieurs experts à expliciter, selon des
méthodes appropriées à leur mode d'inscription,
de façon à respecter la culture de l'organisation.
SOQUIJ retirera du projet plusieurs
bénéfices importants. Le transfert d'expertise permettra
l'acquisition progressive de méthodes de gestion et d'analyse
de textes assistées par ordinateur, car les conseillers
juridiques participent activement à l'enquête cognitive
et aux rencontres d'information et de formation qui accompagnent
le projet. L'explicitation des politiques et procédures,
indispensable pour l'élaboration du système expert,
seront récupérées pour les opérations
quotidiennes. La formation des stagiaires et des nouveaux conseillers
juridiques devrait en être accélérée
et un meilleur service aux utilisateurs devrait en découler.
Comme le système expert interviendra en amont des opérations
actuellement automatisées, celles de la saisie des résultats
de l'analyse intellectuelle des jugements, il favorisera le processus
de décision et permettra aux conseillers juridiques de
réserver leur temps et leur expertise à des tâches
de plus haut niveau, comme la gestion de la connaissance du système
expert. La mise à disposition d'un nombre croissant de
jugements sera accélérée, sans trop d'impact
sur les ressources humaines. Les résultats des analyses
de co-occurrences et de "clusters" pour les rubriques
de classification, les descripteurs et les unités lexicales
des textes pourraient être réutilisés dans
la conception d'outils d'aide au repérage dans la lignée
des travaux menés au CNRS en France(Courtial, 1985) ou
dans des organismes comme La National Library of Medicine (Doszkocs,
1983).
Quant à l'équipe
de recherche, elle trouve dans ce projet un merveilleux banc d'essai
pour tester à grande échelle des méthodologies
et des technologies élaborées dans des recherches
précédentes portant sur l'analyse de textes, l'indexation
et le contrôle du vocabulaire assistés par ordinateur,
la gestion des bases de données textuelles, l'extraction
de connaissances et la mise au point des logiciels SATO et ACTE.
BIBLIOGRAPHIE DES SOURCES CITÉES
Bertrand-Gastaldy, S., 1992. Avec la collaboration de G. Pagola. Le contrôle du vocabulaire et l'indexation assistés par ordinateur; Une approche méthodologique pour l'utilisation de SATO. Université de Montréal, École de bibliothéconomie et des sciences de l'information; janvier 1992. 612 p. Courtial, J.-P. Comparaison de cartes leximappe obtenues par indexation manuelle et par indexation lexicale automatique d'un échantillon de 12 articles; conséquences sur l'interprétation des différents types d'indexation et sur l'interprétation des cartes Leximappe. Documentaliste ; 22(3); mai-juin 1985: 102-107. Chaumier, Jacques; Déjean, Martine, 1992. L'indexation assistée par ordinateur: principes et méthodes. Documentaliste; sciences de l'information; 29(1); 1992: 3-6. Daoust, F. SATO (système d'analyse de texte par ordinateur); version 3.6; Manuel de référence. Université du Québec à Montréal; Centre d'analyse de textes par ordinateur (ATO); janvier 1992. David, C.. Élaboration d'une méthodologie d'analyse des processus cognitifs dans l'indexation documentaire. Montréal: Université de Montréal, Département de communication; septembre 1990. (mémoire de maÎtrise). Didier, E.. Langues et langages du droit. Montréal: Wilson & Lafleur; 1990. Doszkocs, T.E. CITE NLM: Natural language searching in an online catalog. Information Technology and Libraries; 2(4): December 1983: 364-380. Endres-Niggemeyer, B. A procedural model of abstracting, and some ideas for its implememtation. In : H. Czap et W. Nedobity, eds. TKE'90: Terminology and Knowledge Engineering; Proceedings of the Second International Congress on Terminology and Knowledge Engineering, 2-4 October 1990, University of Trier (FRG), Frankfurt: Indeks Verlag; 1990: 230-243. Farrow, J. F. A cognitive process model of document indexing. Journal of Documentation; 47(2); June 1991:149-166. Grishman, R.; Kittredge, R., eds. Analyzing language in restricted domains: sublanguage description and processing. Hillsdale: LEA; 1986. 246 p. Griswold, R., 1990. The ICON Programming Language. : Prentice-Hall; 1990. Kittredge, R.; Lehberger, J., eds. Sublanguage: studies language in restricted domains. De Gruyter; 1982. 240 p. Meunier, J.-G., Bertrand-Gastaldy, S.; Lebel, H.. A call for enhanced representation of content as a means of improving on-line full-text retrieval. International Classification; 14(1), 1987: 2-10. Paquin, L.-C., 1992a. La lecture experte. Technologie, idéologie et pratique; 10(2-4); 1992: 209-222. Numéro spécial consacré au colloque "Intelligence artificielle et sciences sociales". Paquin, L.-C., 1992b. ACTE 1.0; Manuel de référence. Montréal: Université du Québec à Montréal, Centre d'analyse de texte par ordinateur; mars 1992. Poirier, D.. Pour des résumés adéquats de jurisprudence québécoise et canadienne: une étude du document jurisprudentiel, de sa structure, de ses citations, de son rôle et de sa spécificité. Montréal: Université de Montréal, École de bibliothéconomie et des sciences de l'information; 1985.
Todeschini, C.; Farrell, M.P. "An expert
system for quality control in bibliographic databases." Journal
of the American Society for Information Science ; 40(1); 1989:
pp.1-11. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||